Does a torch.utils.data.Dataset worker initiate fetching when its iterator is called? __iter__? __next__? Once the DataLoader collates the batch, does the worker automatically start pulling the next one or does it wait idly until the iterator is called again?
TLDR: At what point does it fetch? What triggers the fetch?
The workers should start loading the data once the iterator is created and preload the prefetch_factor*num_workers batches. Afterwards each next call will consume a batch and let the corresponding worker load the next batch.
Here is a small example showing this behavior:
class MyDataset(Dataset):
def __init__(self):
self.data = torch.randn(512, 1)
def __getitem__(self, idx):
worker_info = torch.utils.data.get_worker_info()
print("loading idx {} from worker {}".format(
idx, worker_info.id))
x = self.data[idx]
return x
def __len__(self):
return len(self.data)
dataset = MyDataset()
loader = DataLoader(dataset, num_workers=8, batch_size=2)
loader_iter = iter(loader) # preloading starts here
# with the default prefetch_factor of 2, 2*num_workers=16 batches will be preloaded
# the max index printed by __getitem__ is thus 31 (16*batch_size=32 samples loaded)
data = next(loader_iter) # this will consume a batch and preload the next one from a single worker to fill the queue
# batch_size=2 new samples should be loaded
Thanks for the answer above. I wanted to know where exactly in the dataloader.py “the next call would consume the current batch and load the next batch” ?
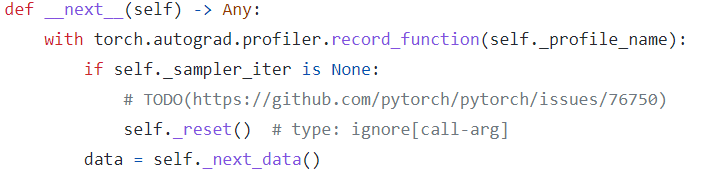
As far as I understood, the __next__ function calls the `_next_data.
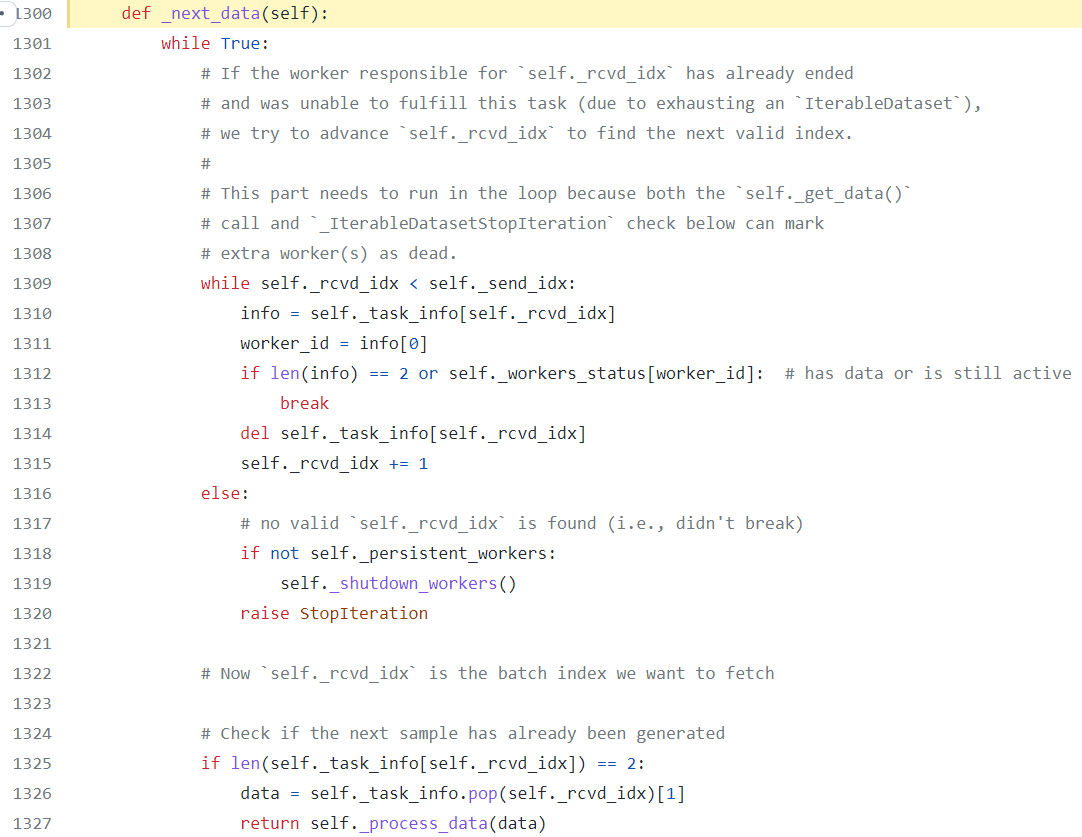
and finally, in the process_data method, the try_put_index is being called which fetches the next index from sampler and gets the next active worker and assigns the batch to the worker.
On the other hand, for consuming the current index, the worker.py has a line to perform a indexqueue.get that gets the current index from the queue and loads the corresponding batch using fetcher.fetch.
The description of the call chain sounds reasonable based on the posted screenshots of the code, but to be sure I would recommend to verify it by either stepping through it with a debugger or by e.g. adding debug print statements to see how the execution is done.
Also related to this thread.
Does this mean that loader_iter = iter(loader) only needs to be called once in a training loop because each time a batch is consumed via the call next(loader_iter), a batch will be pre-loaded to maintain the number of pre-loaded batches?
I read this and thought: when the iterator is exhausted it will automatically start again from index 0 when persistent_workers=True ? The docs do not say anything about that…
i am currently calling iter(dataloader) at the start of every epoch, and I was wondering if in the background the next prefetching happens or not, but it sounds like I don’t need to worry about re-creating the iterator before processing the last batch of one epoch? Do I not need to re-create it at all?