Hello,
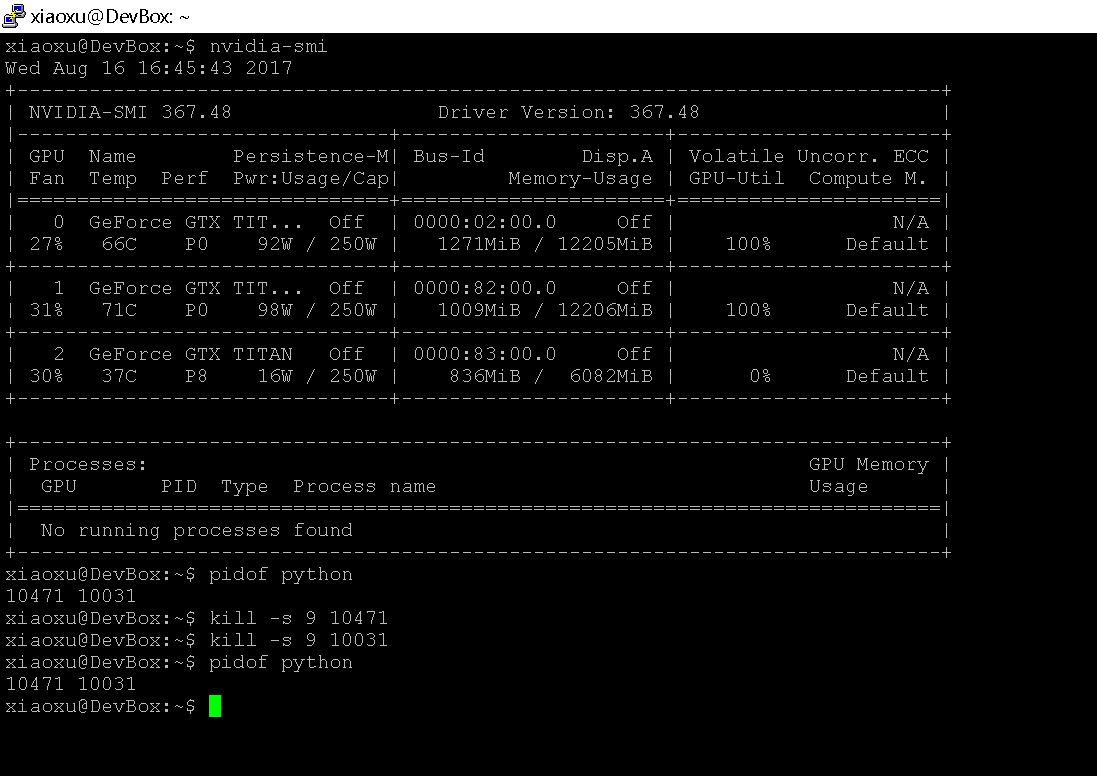
When I shut down the pytorch program by kill, I encountered the problem with the GPU(I opened two programs at the same time and then turned off).
When i use kill to close the program,GPU is still occupied.Then I found that there were two PIDs that could not kill.
What’s wrong ? thank you ?
I also had the same problem. The admin had to reboot every time this happened. Something is quite wrong in the DataParallel.
Also I’ve often experienced the following:
running on multiple GPUs with DataParallel and DataLoader (num_worker = 16), try to terminate the process with ctrl+c then program freezes. Gpus hang, including nvidia-smi or other GPU related work.
I am still encountering the GPU hang problem today, but my case is not Pytorch related.
I’m using Win7 with CUDA 10.2, writing C++ code with CUDA runtime API. Sometimes when I hit Ctrl-C, the GPU hangs and the process is in some sort of zombie state and unkillable, then I have to reboot.
I conjecture that when the host code is submitting a kernel job and the kill signal arrives this will happen, without concrete evidence. If that’s the case, we might need to catch the kill signal in our code to allow graceful exit of CUDA.
@feipan664’s solution worked. But, how can we prevent this issue in advance? PID in nvidia-smi shows just the main PID of the job. And, killing that just kills the main PID, remaining intertwined PIDs.