I want to use a numpy-based upsampling function in training a deep learning network.
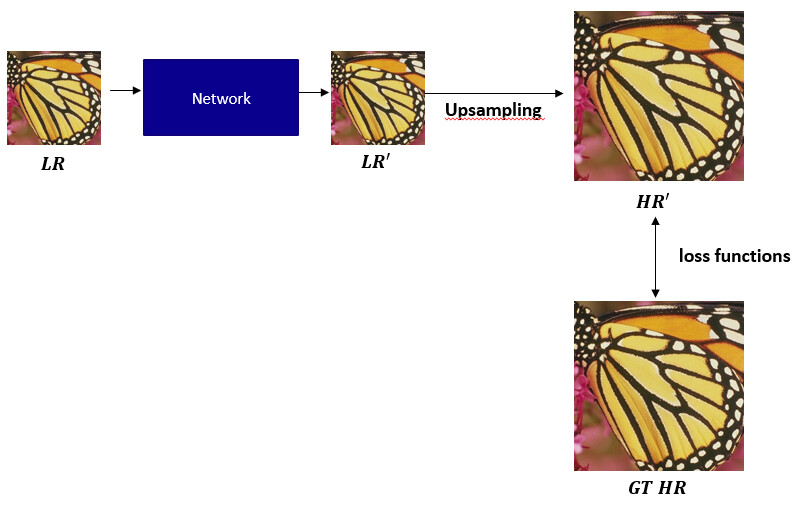
I want to use the loss function between the upsampling result and the GT to train the network to preprocess the image before upsampling.
def forward(self, x):
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
images = []
for batch in range(x.shape[0]):
single_img = x[batch, :, :, :].squeeze(0)
np_single = tensor_to_numpy(single_img.cpu().detach())
upsampled = numpy_based_upsample(np_single)
up_tensor = numpy_to_tensor(upsampled).unsqueeze(0)
images.append(up_tensor)
out = torch.cat(images, dim=0).cuda()
return x, out
I wrote the code as described above, and I encountered error message
“RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn”
So, I changed the code as follow
out = torch.cat(images, dim=0).cuda().requires_grad_(True), but upon inspecting the results, it seems that the network hasn’t learned properly. In such a case, how should I resolve this problem?
(The reason why I wrote the code as above is that the function based on numpy is for images of (H, W, C), But the tensor image of the network is the shape of (B, C, H, W).)