The OneCycleLR learning rate scheduler is designed around Leslie Smith’s concept of super-convergence. But presumably super-convergence is not always possible.
For example, in the LR scheduler plot below, there is not a classic example of descending training loss with greater learning rates:
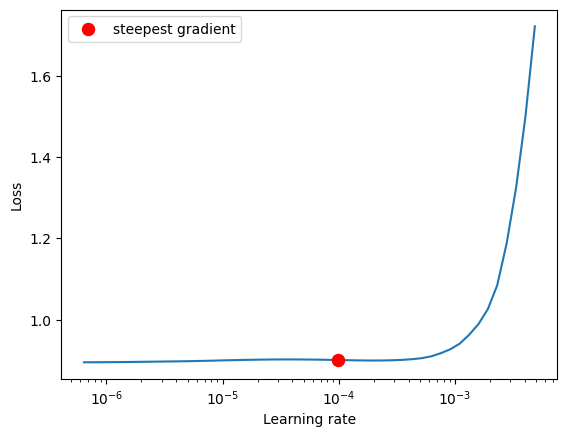
Is this an example where the OneCycleLR approach should be avoided, favoring a more classical learning rate schedule instead? Or is there no real connection between a descending loss in an LR Finder slope and the OneCycleLR aside from the fact that they were both described by Leslie Smith?