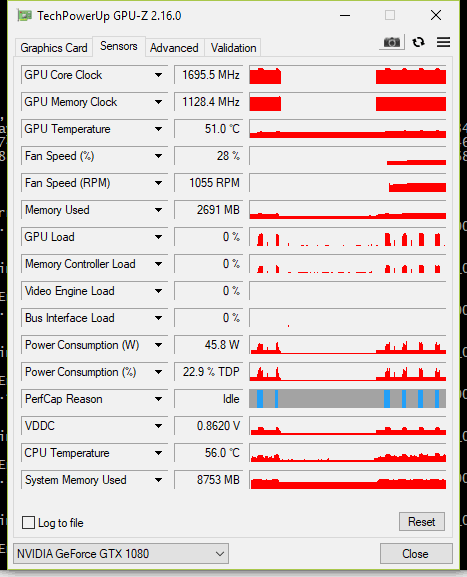
The problem is , I noticed when training, the GPU utilization is very bad, and at first I thought maybe its because I didn’t make my parameters use cuda() it seems a lot is being off loaded to CPU instead of GPU. here is a screenshot during training.
Not only the GPU utilization is not fixed, even worse, the backpropagation now wont work for my parameter at all and it wont get tuned!
If I remove .cuda(), it gets trained fine!
So here I’m facing two issues,
Why using .cuda() prevents my parameter from participating in the optimization process?
Why is GPU not utilized like before?
by the way, my model uses .cuda() ( the CrossEntropyLoss also has .cuda() but it seems it works fine without it too! I mean it seems it doesn’t make any difference whether I use .cuda() on criterion)
To use cuda, you should create your model as usual then call model.cuda() to send all parameters of this model (and other stuff in the model) to the gpu. Then you need to make sure that your inputs are on the gpu as well input = input.cuda(). Then you can forward on the gpu by doing: model(input).
Note that model.cuda() will change the model inplace while input.cuda() will not change input inplace and you need to do input = input.cuda().
async=True for the target is most likely useless here (unless you specifically put it in pinned memory) so you can remote it
Variables don’t exist anymore, you can remove input_var = torch.autograd.Variable(input) and just use input where you have input_var. Same for the target.
Replace output.data with output.detach() that is the new way to do it. It works nicely with the autograd engine and will detect some forbidden behavior that the old .data was not able to do.
Now if you have args.use_cuda=True, your model will use the GPU.
Keep in mind that if your model or input is very small, you might not use the gpu very efficiently and thus gpu usage will remain small. You need to perform large enough ops for the gpu to be properly used. Increasing the batch size is an easy way to increase the amount of work for each op.
Thanks a lot. that was it:) my model was way too tiny to begin with, even when I used batchsize of 512, the network was only 3~4 layers with like 10~30K parameters and it wouldnt need much GPU load to begin with
Thanks a gazillion times
Could you please tell why using .cuda() on a parameter prevents it from participating in the optimization process? Removal of .cuda() from nn.Parameter() woks fine. I was facing the same issue.
If your original Tensor is a leaf (a Tensor for which the .grad field is populated when you call .backward()), and you call .cuda() on it. Then the result is not a leaf because it was created in a differentiable manner. So you need to move it to cuda() before creating the nn.Parameter().
If your problem persist, please send a small code example that shows your issue.