During inference with an OCR model, experimental results indicate a non-linear increase in GPU memory usage as the batch size is raised.
The specific experimental method involved taking a real image and resizing it to various sizes using OpenCV’s resize method with linear interpolation. The batch size was increased by duplicating the numpy matrices of the samples.
det_model.eval().cuda()
origin_image = cv2.imread(image_path)
with torch.no_grad():
for tup in itertools.product([i for i in range(640,1000,32)],[i for i in range(640,1000,32)]):
i = tup[0]
j = tup[1]
torch.cuda.empty_cache()
for z in range(1,100):
try:
img = cv2.resize(origin_image,(i,j), interpolation=cv2.INTER_LINEAR)
img = copy_img(batch_size=z, img)
input_for_torch = torch.from_numpy(img).cuda()
print(det_model(input_for_torch))
except RuntimeError as e:
if "CUDA out of memory" in str(e):
print(str(i) + '. ' + "{} × {} batch_size: {}".format(i, j, z) + ' OOM')
By creating child processes that infinitely loop to monitor GPU usage, you obtained peak memory consumption and inference times for each batch size, as shown in the following graph.
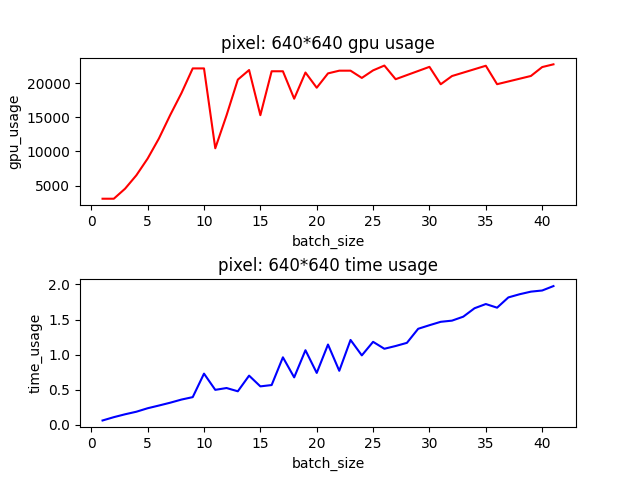
Why did the results as shown in the graph occur?