Hi, @ptrblck , could you tell me where I can find native_layer_norm in the line return std::get<0>(at::native_layer_norm(input, normalized_shape, weight, bias, eps));
Heres what i written in my class which when I use it to train a 124m parameter LLM model. The loss curve looks the exact same (refer to forward pass method below):
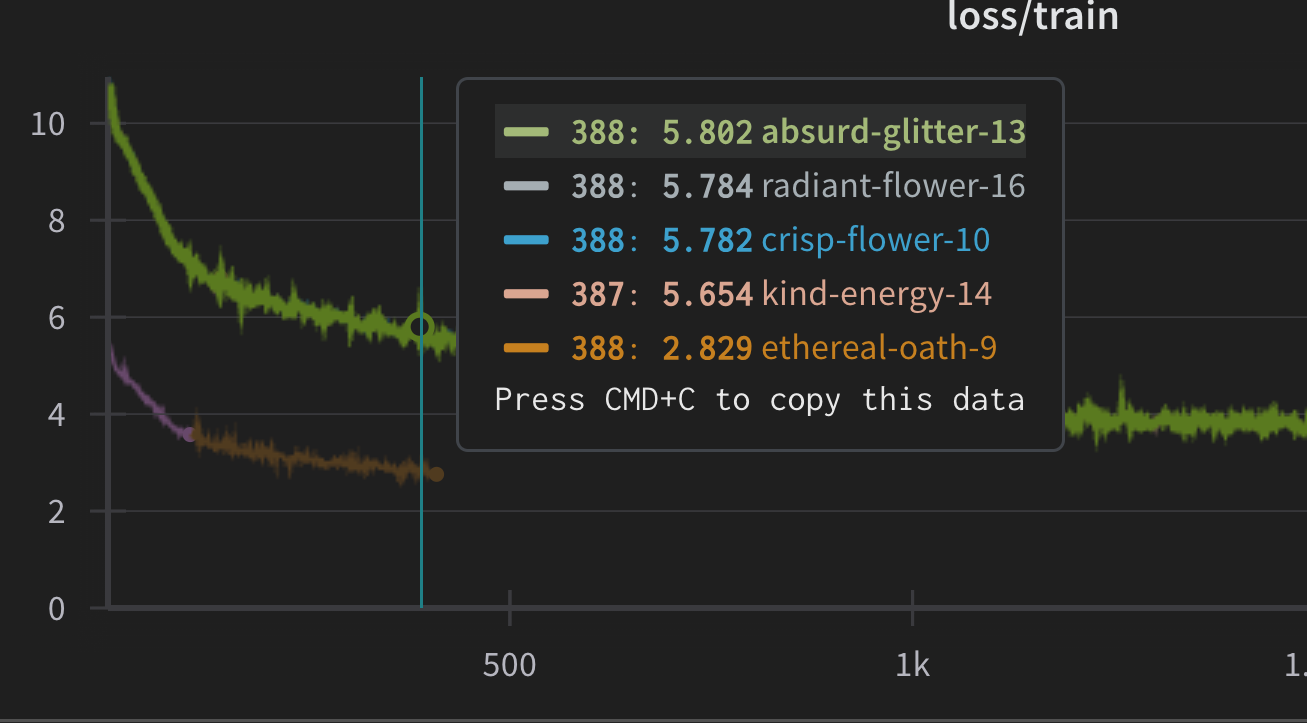
for reference. the run with the layer norm class used below can be seen in the run “radiant-flower-16”. “absurd-glitter-13”, “crisp-flower-10” and “kind-energy-14” are previous runs using torch’s default layernorm class. And hence you can see their loss is very simillar, hence I think my implementation is a direct replica afaik (haven’t tested it beyond this).
P.S. ignore the ethereal-oath-9, that was some bugs with logging.
if you are dealing with text sequence, the target of layernorm should be the last dimension. in your computing, you choosed the first dimension. this might be the reason why the results are different.