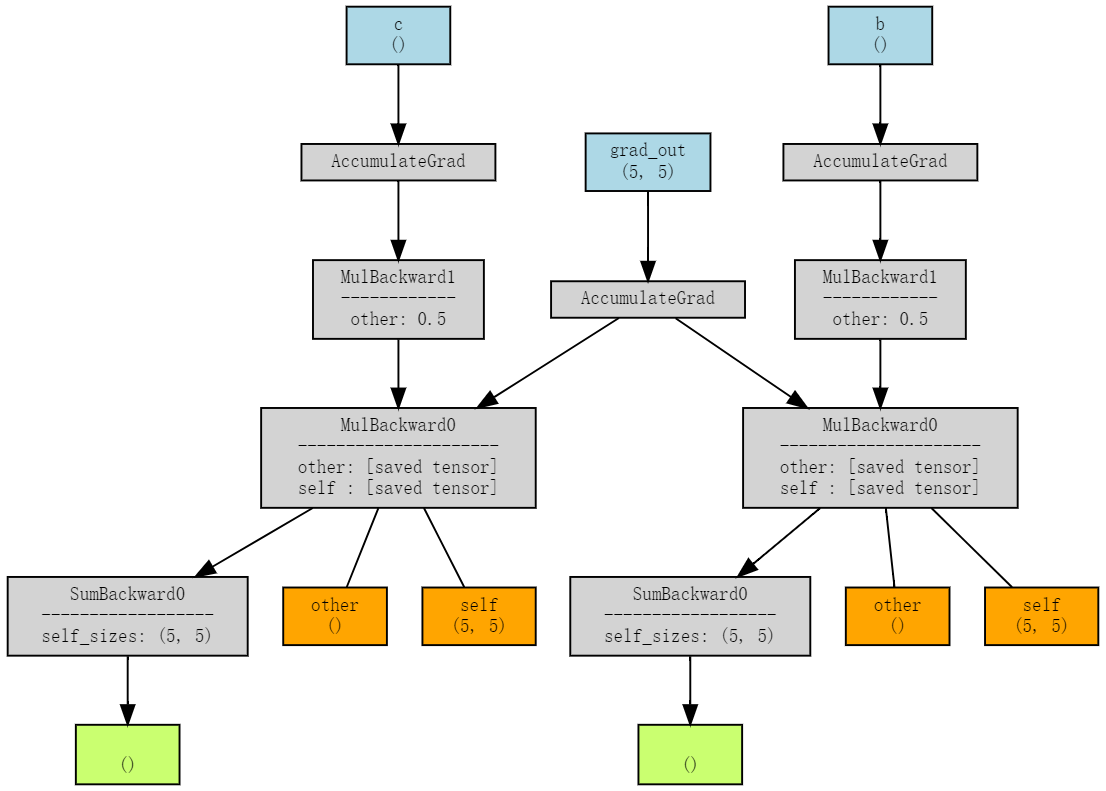
By using nvprof, I managed to trace it down to this kernel information:
void at::native::unrolled_elementwise_kernel<at::native::MulScalarFunctor<double, double>, at::detail::Array<char*, 2>, Trivi...(int, at::native::MulScalarFunctor<double, double>, at::detail::Array<char*, 2>, TrivialOffsetCalculator<1, unsigned int>, TrivialOffsetCalculator<1, unsigned int>, at::native::memory::LoadWithCast<1>, at::native::memory::StoreWithCast)
And another kernel is
void at::native::unrolled_elementwise_kernel<at::native::MulFunctor<float>, at::detail::Array<char*, 3>, OffsetCalculator<2, ...(int, at::native::MulFunctor<float>, at::detail::Array<char*, 3>, OffsetCalculator<2, unsigned int>, OffsetCalculator<1, unsigned int>, at::native::memory::LoadWithoutCast, at::native::memory::StoreWithoutCast)
I guess MulFunctor is for same shape multiplication? (MulBackward),
MulScalarFunctor is for an array times a scalar? (MulBackward1).
But I’m also quite curious as how did pytorch auto-generated MulBackward and MulBackward1, etc as in torch/csrc/autograd/generated/Functions.h file.
Edit:
for adcmul op, the torchviz result:
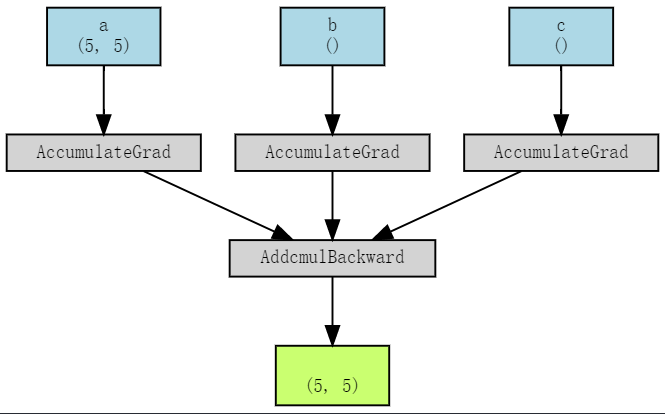
There is a AddcmulBackward, by inspecting into the kernels called using nvprof again, I also see that there is the aforemetioned at::native::MulScalarFunctor like for MulBackward1, but this time the template class is float:
void at::native::vectorized_elementwise_kernel<4, at::native::MulScalarFunctor<float, float>, at::detail::Array<char*, 2> >(int, at::native::MulScalarFunctor<float, float>, at::detail::Array<char*, 2>)
So, I’m curious why in the first case, it’s a double, in the second case, it’s a float?
And here is the simple python test code:
import torch
from torch import nn
from torchviz import make_dot, make_dot_from_trace
# %%
S = 2
device = 'cuda:0'
a = torch.randn(S, S, requires_grad=True, device=device)
b = torch.tensor(0.3, requires_grad=True, device=device)
c = torch.tensor(0.5, requires_grad=True, device=device)
value = 0.5
y = torch.addcmul(a, b, c, value=value)
# %%
# Use a fn to do addcmul/addcdiv, etc
def fn(*inputs):
output = getattr(inputs[0], 'addcmul')(*inputs[1:], value=value)
return output
num_outputs = 1
tupled_inputs = (a, b, c)
output = fn(*tupled_inputs)
# torch.allclose(output, a.addcmul(b, c, value=value))
# %%
grad_out = torch.ones_like(output, requires_grad=True)
def new_func(*args):
input_args = args[:-num_outputs]
grad_outputs = args[-num_outputs:]
outputs = fn(*input_args)
input_args = tuple(x for x in input_args if isinstance(x, torch.Tensor) and x.requires_grad)
grad_inputs = torch.autograd.grad(outputs, input_args, grad_outputs, create_graph=True)
return grad_inputs
tupled_inputs = (a, b, c, grad_out)
# %%
grad_inputs = new_func(*tupled_inputs)
# print(grad_inputs)
# Now try gradgrad
g_b = grad_inputs[1]
gradgrad_out = torch.ones_like(g_b, memory_format=torch.legacy_contiguous_format)
gradgrad_input = torch.autograd.grad(g_b, tupled_inputs, gradgrad_out,
retain_graph=True, allow_unused=True)
# print(gradgrad_input[2])
# # %%
# make_dot(output)
# # %%
# grad_inputs = new_func(*tupled_inputs)
# # %%
# grad_inputs[0]
# # %%
# make_dot(new_func(*tupled_inputs)[1], params={'a': a, 'b': b, 'c': c, 'grad_out': tupled_inputs[-1]})
# # %%
# make_dot(new_func(*tupled_inputs)[2], params={'a': a, 'b': b, 'c': c, 'grad_out': tupled_inputs[-1]})
# # %%
# make_dot(new_func(*tupled_inputs), params={'a': a, 'b': b, 'c': c, 'grad_out': tupled_inputs[-1]})
# # %%
# make_dot(new_func(*tupled_inputs), params={'a': a, 'b': b, 'c': c, 'grad_out': tupled_inputs[-1]}, show_attrs=True)
# # %%
# torch.__version__
With nvprof:
nvprof --print-gpu-trace python test_addcmul.py