I am testing my program on a subset of my data to make sure everything works. I’m experimenting with different loss functions and optimizers. I’m getting the following results:
The figure below uses MSE as the loss, Adam as the optimizer, and takes 250-300 epochs for the loss to plateau. The plateau sits around a loss of 225.
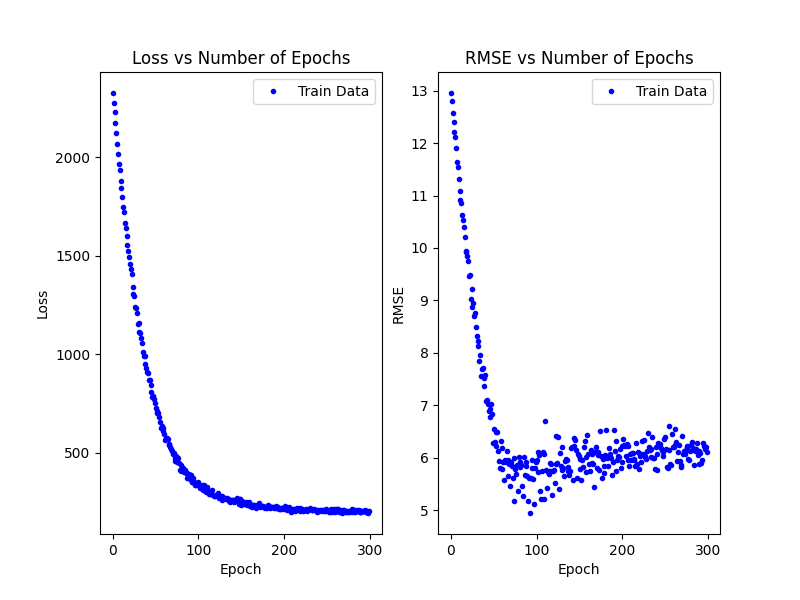
The figure below uses MSE as the loss, Adam as the optimizer, and takes 50-100 epochs for the loss to plateau. The plateau sits around a loss of 214.

The figure below uses L1 as the loss, Adam as the optimizer, and takes ~250 epochs for the loss to plateau.
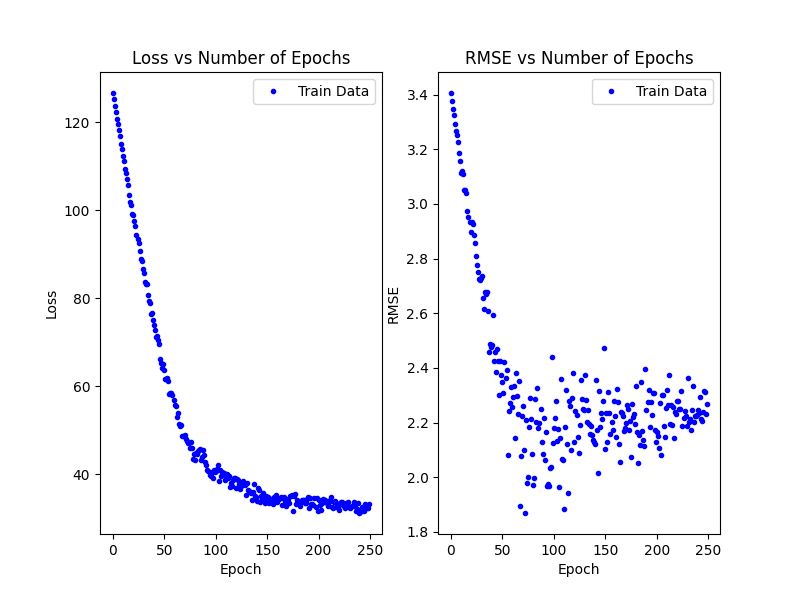
What am I supposed to prefer? Fewer epochs? Or lower loss? Edit: batch size and learning rate for all of the above are exactly the same.
I also am not sure about why my RMSE dips slightly, then increases a little and then levels out. Is this dip normal?