Here is a minimum nontrivial example that make me confused:
Example1 : passed
import torch
x = torch.nn.Linear(3,3)
a = torch.autograd.Variable(torch.randn(2, 3))
for i in range(100):
y = torch.sum(x(a))
y.backward()
Example2 : failed. RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
import torch
x = torch.nn.Linear(3,3)
a = torch.autograd.Variable(torch.randn(2, 3))
y = torch.sum(x(a))
for i in range(100):
y.backward()
What confused me is that in principle, the ‘graph’ will be freed after calling y.backward() in the first example and obviously x,a are contained in the graph. Then x, a will be freed too. So I did not expect the first example will pass since during the second y.backward() call we are not able to locate x and a. The second example is even more confusing to me. Just moving y=torch.sum() outside the loop will create an error.
So my question is: in both cases when the ‘graph’ is created? which autograd.Variables/nn.Module are contained in the graph? If the graph is freed after y.backward() is called, why the first example can pass? Why the second one can’t?
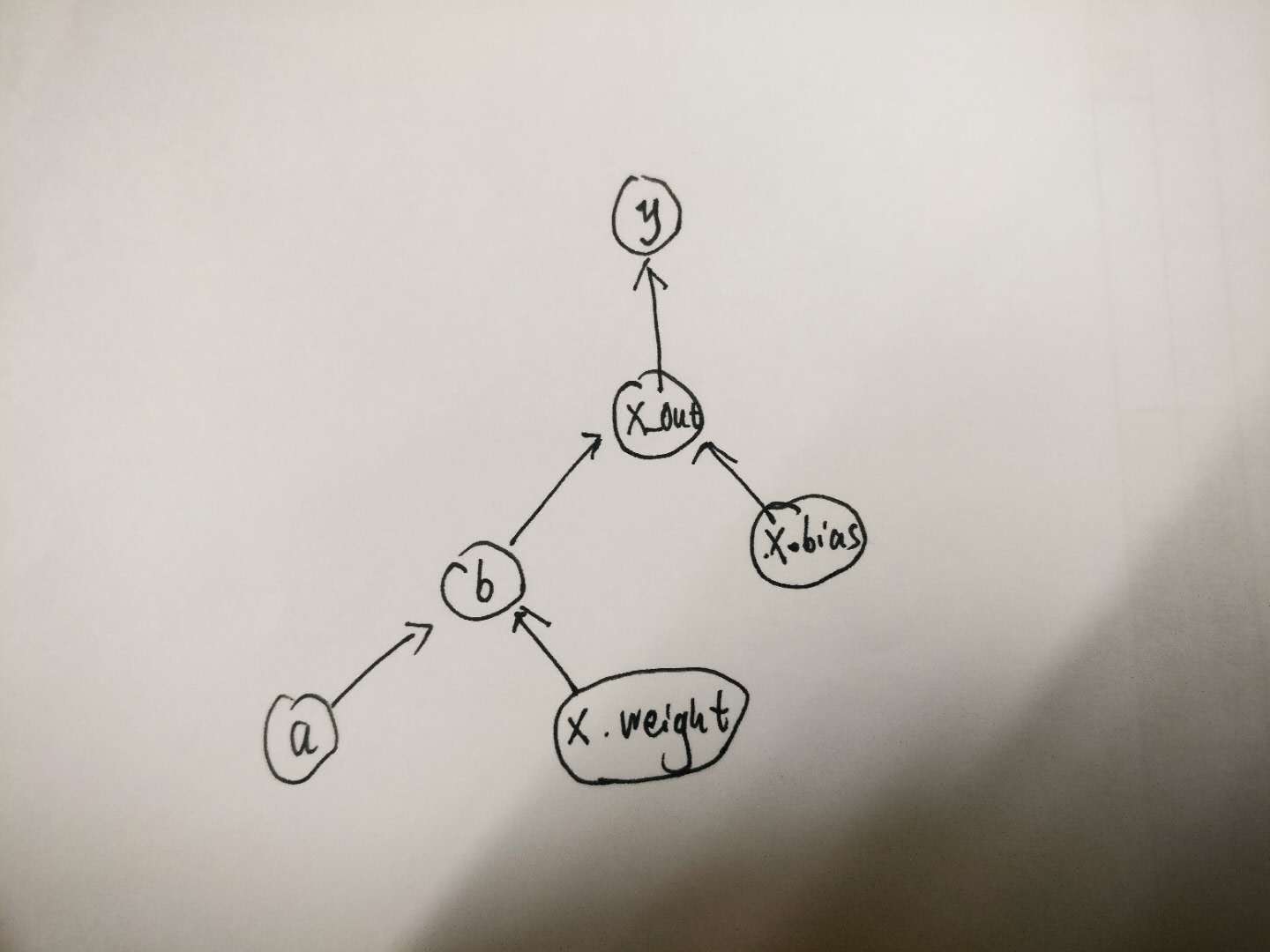
Here is your code with some comment on what is in the graph and what is not, let me know if it helps:
import torch
x = torch.nn.Linear(3,3)
# x is an nn.Module
# It contains two "leaf" Variables which mean a Variable that requires gradients
a = torch.autograd.Variable(torch.randn(2, 3))
# a is a Variable that does not require gradient, has no graph associated to
# it since no operation is done.
for i in range(100):
x_out = x(a)
# x_out is a `Variable` with the associated graphs of all computations
# corresponding to the forward function of x
# Note that all the objects of the graph (Functions and intermediary Variables)
# are only accessible from the python object x_out
y = torch.sum(x_out)
# y has a graph containing the sum operation and all the graph of x_out
y.backward()
# Go through the whole graph associated with y and compute the gradient for
# all the leafs Variable
# To reduce memory usage, all the intermediary Variables are freed.
import torch
x = torch.nn.Linear(3,3)
# nn.Module with two leafs Variables
a = torch.autograd.Variable(torch.randn(2, 3))
# a Variable that does not require grads
y = torch.sum(x(a))
# y contains a Variable with associated to it the graph
# corresponding to the forward function of x and
# the sum Function
for i in range(100):
y.backward()
# First iteration:
# We call backward and free the intermediary Variables of the graph
# Second iteration:
# You try to go through the graph associated with y but it has
# already been cleared
Thanks that’s an excellent explanation! As you explained, in the second example when y.backward() was called the second time the variable ‘a’ was freed and the graph was not built again. That’s the reason why we can not let the gradient flow through. But I’m curious about, was ‘x’ also been freed? x is nn.Module so it is a collection of two leaf variables so in principle it is also an ‘intermediate variable’.
Besides, thanks to your comment I found another question that is not obvious to me. Consider the following code:
import torch
x = torch.nn.Linear(3,3)
a = torch.autograd.Variable(torch.randn(2, 3))
x_out = x(a)
for i in range(100):
y = torch.sum(x_out)
y.backward()
This code will fail, which is unexpected. I think in the second iteration the graph is recreated because we call y=torch.sum(x_out) , which recreates all the Variables associated with y again. The problem disappears if I move x_out in the loop:
import torch
x = torch.nn.Linear(3,3)
a = torch.autograd.Variable(torch.randn(2, 3))
for i in range(100):
x_out = x(a)
y = torch.sum(x_out)
y.backward()
So my guess is, when you apply an operation like torch.sum it won’t recreate a graph. But x_out = x(a) will recreate a graph. Actually it is just a forward() call of the nn.Module object x. After all these experiences my crude conclusion is: the forward() call of nn.Module will recreate a graph associate with its return value. But this is insufficient…
in your example where you call y.backward() in the for loop, when y.backward() is called, the gradient flows all the way to x. And then the input buffers in x are freed, When you call y = torch.sum(x_out) and then y.backward() the second time, the gradients again try to flow all the way to x, but because x needs it’s input to compute correct gradients (and since input was freed in the first backward() call), it will error out. You can declare to y.backward to not free the graph by saying y.backward(retain_graph=True)
But if we inspect a after y.backward(), a still exists. Also upon looking at source of nn.Linear, input is stored as an attribute of the module. What does it mean that “input buffers in x are freed”?
Any python object can be referenced from many places.
When we say “freed” here, it means that the graph will not reference this object anymore. Of course if the user keeps a reference to the object, it won’t be destroyed as it can be used by someone else. But as soon as you remove your other reference to the object, it will be destroyed.
In your first code snippet, the computational graph is created only once, so when you use for loops and try to backward on the graph for more than once without using retain_graph=True, the error will occur.
In you second code example, each time the for loop is executed, a fresh new graph is created and you can backward() through it once. If you try to backward in the loop for a second time, it will also fail:
import torch
x = torch.nn.Linear(3,3)
a = torch.autograd.Variable(torch.randn(2, 3))
for i in range(100):
x_out = x(a)
y = torch.sum(x_out)
y.backward() # fine
y.backward() # fail cause you are trying to backprop on the same net for a second time
Hi,I have couple questions to ask , before showing my question I write an simple code first:
a = torch.tensor(2.0,requires_grad=True)
c = a*5
c.backward() #After back prop,the buffer would be deleted
And if we do it once again,
c.backward()
Apparently, it would give :
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
So the questions are :
1.What does deleting(free) buffer or temporary variable mean ? Does it mean we can’t use those tensors or functions anymore?
2.Can you please show a simple example to show or check if the buffers and temporary variable are deleted after backward?
3.Based on :
if the user keeps a reference to the object, it won’t be destroyed as it can be used by someone else
How do we prevent the buffer or temporary variable being freed after backward?
First a bit more context.
In python, the same object can be used at multiple places and be referenced.
t = torch.rand(10) # Here we create a Tensor
l = [t] # Here the list contains the same Tensor
print(t) # t is accessible
del t # We delete t
print(l[0]) # The other reference to t is still valid and t was not freed.
Same thing the other way
t = torch.rand(10) # Here we create a Tensor
l = [t] # Here the list contains the same Tensor
print(t) # t is accessible
del l # We delete the list that contains the reference to t
print(t) # t still exists
The buffers we save in the computational graph are like in the example above when I save a reference to t in a list.
Freeing the buffers mean deleting the reference held by the computational graph to these buffers. You cannot access them from the computational graph. But other references are still valid.
We don’t have an api to check this. But the backward will delete all the saved buffers.
If you already hold onto another reference they won’t be freed. If you want to keep the reference stored in the graph, you need to pass the keep_graph=True argument to the backward function.
Firstly,Thanks for the clear explanations!
For summary(if wrong,please do correct my statement):
If the object is referenced by more than just one ,after backward ,the only reference would be destroyed is computational graph one,the others that reference this object won’t be freed,If the object is only referenced by computational graph ,after backward,this reference would be freed and not be able to access it from the computational graph.
And one more question is I would like to know what would be freed after back prop :
a = torch.tensor([2.0,3.0],requires_grad = True).view(2,1)
l = nn.Linear(1,3)
y = l(a)
z = y*5
o = torch.sum(z)
o.backward()
During backward,the intermediate variables would be deleted,The word “intermediate” got me thinking that : Does it mean that the all the variables and functions related to operations “between” a and o would be freed or “include” a and o would be freed?
Now what is “intermediate” is a whole other can of worms
Here again, for memory optimization, we only keep what is strictly necessary. And so every Function is responsible to save only what it needs.
This means that there is not general rule of what is an intermediate value, it is dependent on the Function itself.
If you take the multiplication as an example, the definition of it’s derivative is given here as:
- name: mul(Tensor self, Tensor other) -> Tensor
self: grad * other
other: grad * self
This means that the gradient for self is given by grad * other and the gradient for other is given by grad * self.
As you can see, if the gradient for self is needed, only other is required for the backward and only this will be saved.
A hacky way (works in this example, might not work all the time) to see if something is needed for backward is to modify it inplace and see if the backward fails:
import torch
self = torch.rand(10, requires_grad=True).clone() # This one requires gradients
# We do a clone to be allowed to do inplace ops on it later
other = torch.rand(10) # This one does NOT requires gradients
# Backward works
output = self * other
output.backward(torch.ones_like(output))
# Here we only ask for gradients for self. So self should not be saved:
output = self * other
self += 1
output.backward(torch.ones_like(output)) # Works !
# But we need the value of other:
output = self * other
other += 1
output.backward(torch.ones_like(output)) # Fails !