I have a binary classification problem with imbalanced data (1:17 ratio). I want to implement early stopping but not sure which metric value to use as my decider. Actually, if you look at the graph attached, you’ll see accuracy and specificity are similar and sensitivity is the opposite. MCC is pretty low and I’m wondering if I should just use MCC as the decider for early stopping. Or loss? Maybe all hope is not lost and I could train for many more epochs?And how many epochs to check in early stopping and roll back on? Please help, I’m new to early stopping. The plots below represent validation scores of each epoch, trained with unbalanced data and validated on unbalanced data.
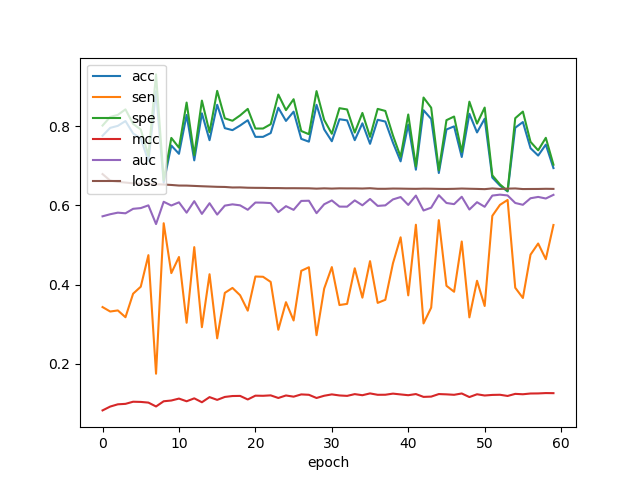
When I train with balanced data (undersampled) and validate with unbalanced data, I get these scores: 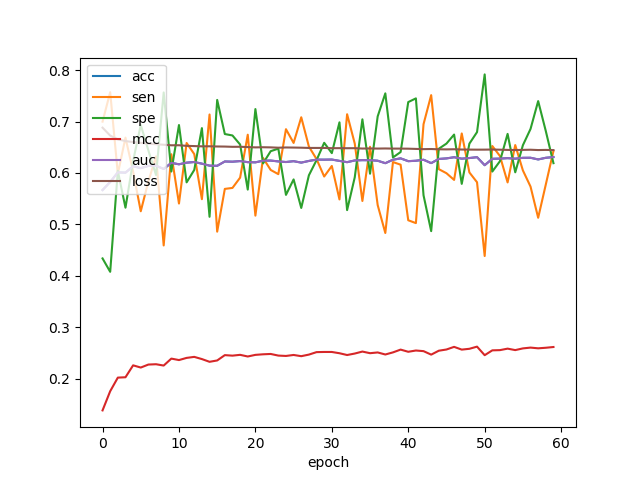
Please help with some advice. Thank you.