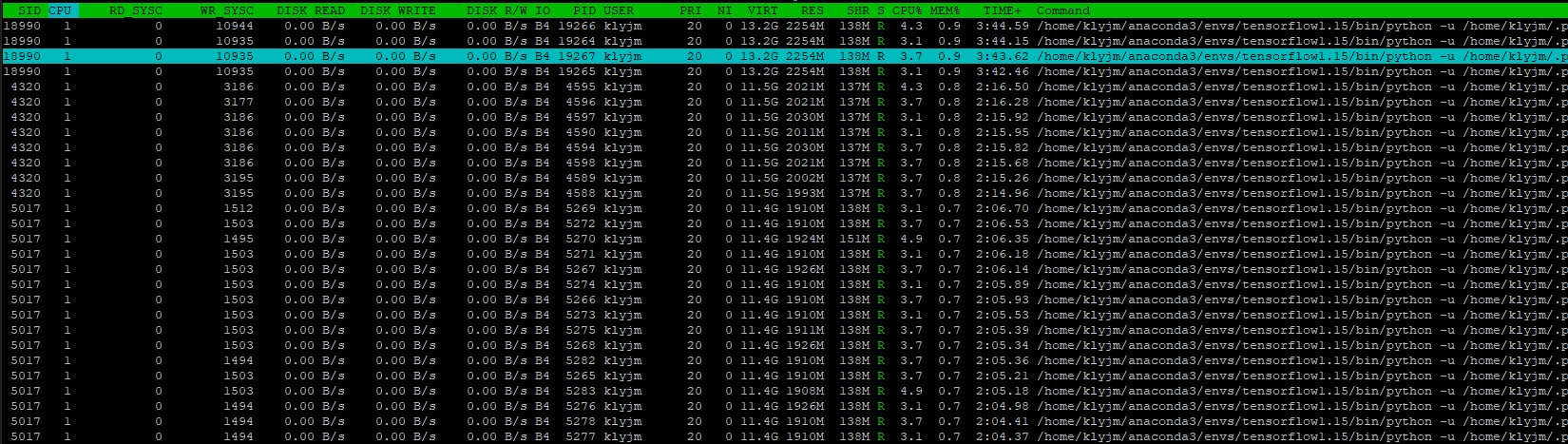
I use Pytorch to train YOLOv5, but when I run three scripts, every scripts have a Dataloader and their num_worker all bigger than 0, but I find all of them are run in cpu 1, and I have 48 cpu cores, do any one knows why?
Hi,
Does CPU here refers to physical CPU or core? Because I guess you have a single CPU no?
In any case, pytorch is not doing anything to pin itself to a given CPU or core. So if that happens, that is from your config.
No, this CPU means core, I have 48 cores
two CPUs with 24 cores per CPU
It is fun that I define two dataloaders in the scripts for train and test with same config, the test dataloader can run in dual cores, but train dataloader can’t. I can’t understand.
It runs on only two cores?
Or on both CPUS?
I have 2 cpus with 24 cores per cpu, and I set num_workers=N > 1. There are N threads of train loader and N threads of test loader, but all these train threads only run in cpu core 1, the test threads can randomly run on N cores.
I have 2 cpus with 24 cores per cpu, and I set num_workers=N > 1. There are N threads of train loader and N threads of test loader, but all these train threads only run in cpu core 1, the test threads can randomly run on N cores.
Note that dataloader create processes, not threads for its workers.
You might want to check that you don’t have core restrictions when you create the train loader.
I even don’t know how to restrict the number of core 
I can show the code.
dataloader, dataset = create_dataloader(train_path, train_label_path, imgsz, batch_size, gs, opt,
hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=rank,
world_size=opt.world_size, workers=opt.workers, isTrain=True)
testloader = create_dataloader(test_path, test_label_path, imgsz_test, total_batch_size, gs, opt,
hyp=hyp, augment=False, cache=opt.cache_images, rect=True, rank=-1,
world_size=opt.world_size, workers=opt.workers, isTrain=False)[0]
def create_dataloader(path, label_path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False,
rank=-1, world_size=1, workers=8, isTrain=False):
# Make sure only the first process in DDP process the dataset first, and the following others can use the cache.
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels(path, label_path, imgsz, batch_size,
augment=augment, # augment images
hyp=hyp, # augmentation hyperparameters
rect=rect, # rectangular training
cache_images=cache,
single_cls=opt.single_cls,
stride=int(stride),
pad=pad,
rank=rank,
data_debug=False,
isTrain=isTrain)
batch_size = min(batch_size, len(dataset))
nw = min([os.cpu_count() // world_size, batch_size if batch_size > 1 else 0, workers]) # number of workers
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset) if rank != -1 else None
dataloader = InfiniteDataLoader(dataset,
batch_size=batch_size,
num_workers=nw,
sampler=train_sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn)
return dataloader, dataset
class InfiniteDataLoader(torch.utils.data.dataloader.DataLoader):
'''
Dataloader that reuses workers.
Uses same syntax as vanilla DataLoader.
'''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler)
def __iter__(self):
for i in range(len(self)):
yield next(self.iterator)
class _RepeatSampler(object):
'''
Sampler that repeats forever.
Args:
sampler (Sampler)
'''
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
You can find that the train loader and the test loader are create by the same function and without restriction of core.
I am not sure how this will interact with distributed I admit…
In any case, since all the threads that you show in the htop process above are idle. It doesn’t matter that they are all on the same cpu/core at the moment. The OS will move them around if they are actually active at the same time?
Yes. Just like htop, it will run in different cores at different time. So the dataloader only run in core 1 is strange when there are 48 cores active.
If they are never used at the same time, it is actually more efficient to have them all on the same core. As the core is “warm”. Moving them to a different one would be bad.
But again, this is OS scheduler business. 
Maybe, but the utils of CPU/GPU/DISK are all low, it is very strange.
Hi @klyjm!
I may have missed this above, but what’s your RAM freq and how does it compare to your CPU? Could you be suffering from insufficient RAM speed or a mismatch between the freq of your RAM and CPU? I’d poke around in the BIOS if you haven’t already. Also, keep in mind that overclocking RAM has seemed to have unpredictable effects for me in the past. Sometimes it seems to help, sometimes to hurt.
Good luck!
–SEH
There is no overlocking RAM, and other code run well. I am trying to rebuild the devlopment enviroment.
Gotcha. Only thing I could think of… Sorry! Issues like this can be soooooo frustrating. I’ll let u know if I can think of anything else. Hope you figure it out soon!
Hi,
I don’t think you should focus on that number so much.
Many process/threads are created when you run pytorch and most of them will be fairly idle. And the current device/core where they sit doesn’t mean anything unless they are actually doing something.
In particular, if you check during testing, then I would expect the processes from the testing dataloader to do stuff at the same time and so to be scheduled on different cores.
But the training workers don’t do anything so they will just stay idle whereever they are.
And I expect it to be the oposite during training where the training processes are scheduled on different cores and the test ones idle somwhere.
I update the version of python to 3.8, and there is no bug. I think this maybe the bug of old version python, just like 3.6.