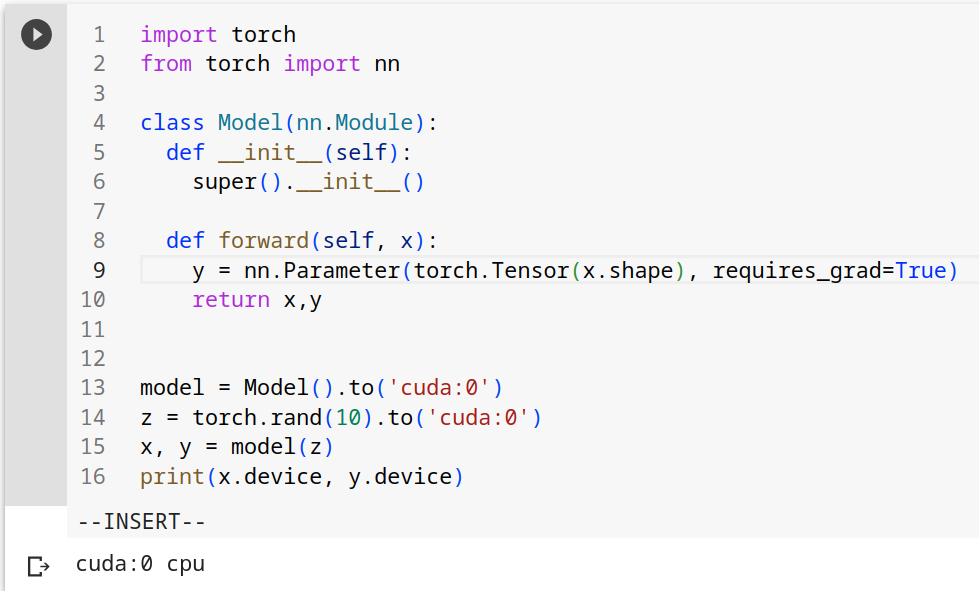
I am encountering an issue with my PyTorch model that has been moved to the GPU using to('cuda:0'). When the model creates a new tensor inside its forward method, the tensor does not get placed on the GPU and instead remains on the CPU.
To better illustrate the problem, I have provided an MWE below:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
y = torch.Tensor(x.shape)
y[::2] = x[::2]
y[1::2] = x[1::2]
return x, y
model = Model().to('cuda:0')
z = torch.rand(4).to('cuda:0')
x, y = model(z)
print(x.device, y.device)
The output of this code indicates that x is located on the GPU (cuda:0), but y remains on the CPU (cpu).
I was expecting both x and y to be located on the GPU (cuda:0). Can someone please help me understand why the newly spawned tensor y does not get placed on the GPU even though the model is on the GPU?
I’ve also tried y = torch.nn.Parameter(torch.Tensor(x.shape), requires_grad=False), but it didn’t work too!
I appreciate any insights or suggestions to resolve this issue. Thank you for your assistance!
That’s not necessarily true. While .to() will be applied recursively to all registered submodules, parameters, and buffers, you are still free to move different parameters to different devices, e.g. to implement model sharding. The model thus does not have a .device attribute, but every parameter and buffer etc.
I’m unsure what you want to tell with your image since this behavior is expected as already mentioned. You are also neither using the _like methods nor pass the device attribute to the tensor creation but instead are using the same failing code from before.
Thank you for your consideration. I have sent the picture for this phrase: That’s not necessarily true. Perhaps there was a misunderstanding on my part.
By the way, as I mentioned before, I expected to get the tensor on the GPU when the model was on the GPU, but I was mistaken. I have resolved my issue with device.