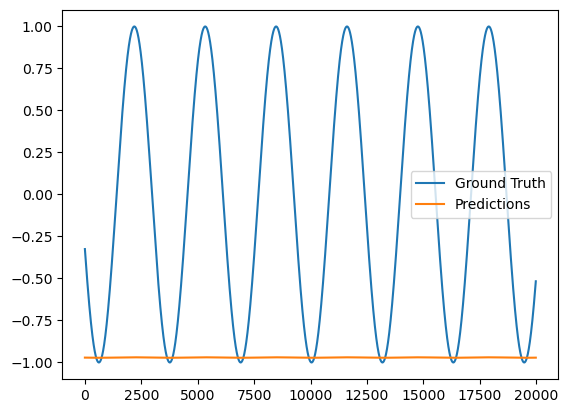
I created an LSTM model, but the prediction result is a straight line. After investigation, there is an error in the backpropagation process. However, I have not been able to find out what went wrong.
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
timesteps = 10;
L = 1;
batch_size = 16;
Epoch = 1;
timespaces=np.linspace(0,10,50000);
data=np.sin(timespaces * 10);
data=np.reshape(data, (-1, 1));
plt.plot(timespaces, data)
plt.show()
train_len=(int)(len(data) * 0.6);
train_data=data[:train_len]; # (30000, 1)
test_data=data[train_len:]; # (20000, 1)
print(train_data.shape);
print(test_data.shape);
plt.plot(timespaces[:train_len],train_data);
plt.plot(timespaces[train_len:],test_data);
plt.show();
def divide(data,timesteps,L):
X,Y=[],[];
for i in range(len(data) - timesteps):
x = data[i:i+timesteps];
y = data[i+timesteps+L-1];
X.append(x);
Y.append(y);
return X,Y;
def divide_batch(data,batch_size):
X = [];
for i in range(len(data)):
if((i + 1) * batch_size - 1 > len(data) - 1):
break;
x = data[i * batch_size : (i + 1) * batch_size];
X.append(x);
return X;
train_X,train_Y = divide(train_data,timesteps,L);
test_X,test_Y = divide(test_data,timesteps,L);
train_X = torch.tensor(train_X).to(torch.float32);
train_Y = torch.tensor(train_Y).to(torch.float32);
print("before:");
print("train_X.shape:");
print(train_X.shape);
print("train_Y.shape:");
print(train_Y.shape);
train_X = divide_batch(train_X,batch_size);
train_Y = divide_batch(train_Y,batch_size);
train_X = torch.tensor([item.detach().numpy() for item in train_X] ).to(torch.float32);
train_Y = torch.tensor([item.detach().numpy() for item in train_Y]).to(torch.float32);
print("after:");
print("train_X.shape:");
print(train_X.shape);
print("train_Y.shape:");
print(train_Y.shape);
test_X = torch.tensor(test_X).to(torch.float32);
test_Y = torch.tensor(test_Y).to(torch.float32);
print("before:");
print("test_X.shape:");
print(test_X.shape);
print("test_Y.shape:");
print(test_Y.shape);
test_X = divide_batch(test_X,batch_size);
test_Y = divide_batch(test_Y,batch_size);
test_X = torch.tensor([item.detach().numpy() for item in test_X] ).to(torch.float32);
test_Y = torch.tensor([item.detach().numpy() for item in test_Y]).to(torch.float32);
print("after:");
print("test_X.shape:");
print(test_X.shape);
print("test_Y.shape:");
print(test_Y.shape);
class LSTM(object):
def __init__(self,timesteps,batch_size,input_size,hidden_size,output_size):
self.times = 0;
self.timesteps = timesteps;
self.batch_size = batch_size;
self.input_size = input_size;
self.hidden_size = hidden_size;
self.output_size = output_size;
self.Wfh,self.Wfx,self.bf = self.Weight_bias(self.input_size,self.hidden_size);
self.Wih,self.Wix,self.bi = self.Weight_bias(self.input_size,self.hidden_size);
self.Woh,self.Wox,self.bo = self.Weight_bias(self.input_size,self.hidden_size);
self.Wch,self.Wcx,self.bc = self.Weight_bias(self.input_size,self.hidden_size);
self.Wp = torch.randn(self.hidden_size,self.output_size) * 0.01;
self.bp = torch.randn(self.output_size) * 0.01;
self.f = torch.zeros(self.batch_size,self.hidden_size);
self.i = torch.zeros(self.batch_size,self.hidden_size);
self.o = torch.zeros(self.batch_size,self.hidden_size);
self.ct = torch.zeros(self.batch_size,self.hidden_size);
self.h = torch.zeros(self.batch_size,self.hidden_size);
self.c = torch.zeros(self.batch_size,self.hidden_size);
self.fList = [];
self.iList = [];
self.oList = [];
self.ctList = [];
self.hList = [];
self.cList = [];
self.preList=[];
self.fList.append(self.f);
self.iList.append(self.i);
self.oList.append(self.o);
self.ctList.append(self.ct);
self.hList.append(self.h);
self.cList.append(self.c);
def Weight_bias(self,input_size,hidden_size):
return (torch.randn(hidden_size,hidden_size) * 0.01,
torch.randn(input_size,hidden_size) * 0.01,
torch.randn(hidden_size) * 0.01);
def Weight_bias_grad(self,input_size,hidden_size):
return (torch.zeros(hidden_size,hidden_size) * 0.01,
torch.zeros(input_size,hidden_size) * 0.01,
torch.zeros(hidden_size) * 0.01);
def forward(self,x):
'''
x => (timesteps,batchsize,inputsize) => (10,16,1)
x[i] => (batchsize,inputsize) => (16,1)
Wxf => (inputsize,hiddensize) => (1,1)
Whf => (hiddensize,hiddensize) => (1,1)
bf => (hiddensize) => (16,1)
h => (batchsize,hiddensize) => (16,1)
c => (batchsize,hiddensize) => (16,1)
(batchsize,inputsize) @ (inputsize,hiddensize) + (batchsize,hiddensize) @ (hiddensize,hiddensize) => (batchsize,hiddensize)
'''
for i in range(self.timesteps):
self.times += 1;
self.f = self.Sigmoid_forward(self.hList[-1] @ self.Wfh + x[i] @ self.Wfx + self.bf);
self.i = self.Sigmoid_forward(self.hList[-1] @ self.Wih + x[i] @ self.Wix + self.bi);
self.o = self.Sigmoid_forward(self.hList[-1] @ self.Woh + x[i] @ self.Wox + self.bo);
self.ct = self.Tanh_forward(self.hList[-1] @ self.Wch + x[i] @ self.Wcx + self.bc);
self.c = self.f * self.cList[-1] + self.i * self.ct;
self.h = self.o * self.Tanh_forward(self.c);
self.fList.append(self.f);
self.iList.append(self.i);
self.oList.append(self.o);
self.ctList.append(self.ct);
self.hList.append(self.h);
self.cList.append(self.c);
return self.prediction();
def prediction(self):
pre = self.hList[-1] @ self.Wp + self.bp;
self.preList.append(pre);
return pre;
def backward(self,x,grad,y_grad):
self.delta_Wfh,self.delta_Wfx,self.delta_bf = self.Weight_bias_grad(self.input_size,self.hidden_size);
self.delta_Wih,self.delta_Wix,self.delta_bi = self.Weight_bias_grad(self.input_size,self.hidden_size);
self.delta_Woh,self.delta_Wox,self.delta_bo = self.Weight_bias_grad(self.input_size,self.hidden_size);
self.delta_Wch,self.delta_Wcx,self.delta_bc = self.Weight_bias_grad(self.input_size,self.hidden_size);
self.delta_Wp = torch.zeros(self.hidden_size,self.output_size) * 0.01;
self.delta_bp = torch.zeros(self.output_size) * 0.01;
self.delta_hList = self.init_delta();
self.delta_cList = self.init_delta();
self.delta_fList = self.init_delta();
self.delta_iList = self.init_delta();
self.delta_oList = self.init_delta();
self.delta_ctList = self.init_delta();
self.delta_hList[-1] = grad;
for k in range(self.times,0,-1):
self.compute_gate_backward(x,k);
self.compute_Weight_bias_backward(x,y_grad);
def init_delta(self):
X = [];
for i in range(self.times + 1):
X.append(torch.zeros(self.batch_size,self.hidden_size));
return X;
def compute_gate_backward(self,x,k):
'''
delta_hk => [16,1]
o => [16,1]
self.Tanh_backward(c) => [16,1]
self.delta_cList[k+1] => [16,1]
self.fList[k+1] => [16,1]
'''
f = self.fList[k];
i = self.iList[k];
o = self.oList[k];
ct = self.ctList[k];
h = self.hList[k];
c = self.cList[k];
c_pre = self.cList[k-1];
delta_hk = self.delta_hList[k];
if(k == self.times):
delta_ck = delta_hk * o * self.Tanh_backward(c);
else:
delta_ck = delta_hk * o * self.Tanh_backward(c) + self.delta_cList[k+1] * self.fList[k+1];
delta_ctk = delta_ck * i;
delta_fk = delta_ck * c_pre;
delta_ik = delta_ck * ct;
delta_ok = delta_hk * self.Tanh_forward(c);
delta_hkpre = delta_fk * self.Sigmoid_backward(h @ self.Wfh + x[k-1] @ self.Wfx + self.bf) * self.Wfh + delta_ik * self.Sigmoid_backward(h @ self.Wih + x[k-1] @ self.Wix + self.bi) * self.Wih +delta_ok * self.Sigmoid_backward(h @ self.Woh + x[k-1] @ self.Wox + self.bo) * self.Woh +delta_ctk * self.Tanh_backward(h @ self.Wch + x[k-1] @ self.Wcx + self.bc) * self.Wch;
self.delta_hList[k-1] = delta_hkpre;
self.delta_cList[k] = delta_ck;
self.delta_fList[k] = delta_fk;
self.delta_iList[k] = delta_ik;
self.delta_oList[k] = delta_ok;
self.delta_ctList[k] = delta_ctk;
def compute_Weight_bias_backward(self,x,y_grad):
self.delta_Wp =(y_grad * self.hList[-1]).mean() * torch.ones(self.hidden_size,self.output_size);
self.delta_bp = (y_grad.mean()) * torch.ones(self.output_size);
for t in range (self.times,0,-1):
'''
self.delta_fList[t] => [16,1]
(self.Sigmoid_backward(self.hList[t] @ self.Wfh + x[t-1] @ self.Wfx + self.bf)) => [16,1]
self.hList[t-1] => torch.Size([16,1])
delta_Wfh => [16, 1]
[16,1] * [16,1] => [16,1]
[16,1].T => [1,16]
[1,16] @ [16,1] => [1,1]
delta_bf => [16,1]
'''
delta_Wfh = (self.delta_fList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wfh + x[t-1] @ self.Wfx + self.bf)).T @ self.hList[t-1];
delta_Wfx = (self.delta_fList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wfh + x[t-1] @ self.Wfx + self.bf)).T @ x[t-1];
delta_bf = self.delta_fList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wfh + x[t-1] @ self.Wfx + self.bf);
delta_Wih = (self.delta_iList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wih + x[t-1] @ self.Wix + self.bi)).T @ self.hList[t-1];
delta_Wix = (self.delta_iList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wih + x[t-1] @ self.Wix + self.bi)).T @ x[t-1];
delta_bi = self.delta_iList[t] * self.Sigmoid_backward(self.hList[t] @ self.Wih + x[t-1] @ self.Wix + self.bi);
delta_Wch = (self.delta_ctList[t] * self.Tanh_backward(self.hList[t] @ self.Wch + x[t-1] @ self.Wcx + self.bc)).T @ self.hList[t-1];
delta_Wcx = (self.delta_ctList[t] * self.Tanh_backward(self.hList[t] @ self.Wch + x[t-1] @ self.Wcx + self.bc)).T @ x[t-1];
delta_bc = self.delta_ctList[t] * self.Tanh_backward(self.hList[t] @ self.Wch + x[t-1] @ self.Wcx + self.bc);
delta_Woh = (self.delta_oList[t] * self.Sigmoid_backward(self.hList[t] @ self.Woh + x[t-1] @ self.Wox + self.bo)).T @ self.hList[t-1];
delta_Wox = (self.delta_oList[t] * self.Sigmoid_backward(self.hList[t] @ self.Woh + x[t-1] @ self.Wox + self.bo)).T @ x[t-1];
delta_bo = self.delta_oList[t] * self.Sigmoid_backward(self.hList[t] @ self.Woh + x[t-1] @ self.Wox + self.bo);
self.delta_Wfh += delta_Wfh.mean() * torch.ones(self.hidden_size,self.hidden_size);
self.delta_Wfx += delta_Wfx.mean() * torch.ones(self.input_size,self.hidden_size);
self.delta_bf += delta_bf.mean() * torch.ones(self.hidden_size);
self.delta_Wih += delta_Wih.mean() * torch.ones(self.hidden_size,self.hidden_size);
self.delta_Wix += delta_Wix.mean() * torch.ones(self.input_size,self.hidden_size);
self.delta_bi += delta_bi.mean() * torch.ones(self.hidden_size);
self.delta_Wch += delta_Wch.mean() * torch.ones(self.hidden_size,self.hidden_size);
self.delta_Wcx += delta_Wcx.mean() * torch.ones(self.input_size,self.hidden_size);
self.delta_bc += delta_bc.mean() * torch.ones(self.hidden_size);
self.delta_Woh += delta_Woh.mean() * torch.ones(self.hidden_size,self.hidden_size);
self.delta_Wox += delta_Wox.mean() * torch.ones(self.input_size,self.hidden_size);
self.delta_bo += delta_bo.mean() * torch.ones(self.hidden_size);
def update(self,lr):
self.Wfh -= self.delta_Wfh * lr;
self.Wfx -= self.delta_Wfx * lr;
self.bf -= self.delta_bf * lr;
self.Wih -= self.delta_Wih * lr;
self.Wix -= self.delta_Wix * lr;
self.bi -= self.delta_bi * lr;
self.Woh -= self.delta_Woh * lr;
self.Wox -= self.delta_Wox * lr;
self.bo -= self.delta_bo * lr;
self.Wch -= self.delta_Wch * lr;
self.Wcx -= self.delta_Wcx * lr;
self.bc -= self.delta_bc * lr;
self.Wp -= self.delta_Wp * lr;
self.bp -= self.delta_bp * lr;
def reset(self):
self.times = 0;
self.fList = [];
self.iList = [];
self.oList = [];
self.cList = [];
self.preList=[];
self.f = torch.zeros(self.batch_size,self.hidden_size);
self.i = torch.zeros(self.batch_size,self.hidden_size);
self.o = torch.zeros(self.batch_size,self.hidden_size);
self.ct = torch.zeros(self.batch_size,self.hidden_size);
self.fList.append(self.f);
self.iList.append(self.i);
self.oList.append(self.o);
self.ctList.append(self.ct);
self.hList = [torch.zeros(self.batch_size,self.hidden_size)];
self.cList = [torch.zeros(self.batch_size,self.hidden_size)];
def Sigmoid_forward(self,x):
return 1.0 / (1.0 + torch.exp(-x));
def Sigmoid_backward(self,x):
return self.Sigmoid_forward(x) * (1 - self.Sigmoid_forward(x));
def Tanh_forward(self,x):
return ((torch.exp(x) - torch.exp(-x)) / (torch.exp(x) + torch.exp(-x)));
def Tanh_backward(self,x):
return 1 - (self.Tanh_forward(x) * self.Tanh_forward(x));
l = LSTM(timesteps,batch_size,1,1,1);
lr = 0.0001;
lossList = [];
for epoch in range(Epoch):
for i in range(len(train_X)):
x = train_X[i].permute(1, 0, 2);
l.forward(x);
pre = l.prediction();
loss = (pre - train_Y[i]) * (pre - train_Y[i]);
loss = loss.mean();
y_grad = (2/len(x)) * (pre - train_Y[i]);
h_grad = y_grad * l.Wp;
l.backward(x,h_grad,y_grad);
l.update(lr);
l.reset();
lossList.append(loss);
print(f"Epoch {epoch},loss:{loss}");
plt.plot(lossList);
plt.title("Loss");
plt.xlabel("Epoch");
plt.ylabel("loss");
plt.show();
preList = [];
truList = [];
for i in range((len(test_X))):
x = test_X[i].permute(1, 0, 2);
preList.append(l.forward(x));
truList.append(test_Y[i]);
def add(data):
ls = [];
for i in range(len(data)):
for j in range(len(data[i])):
ls.append(data[i][j]);
return ls;
preList = add(preList);
preList = torch.tensor([item.detach().numpy() for item in preList]);
print(preList.shape); # torch.Size([896, 1])
truList = add(truList);
truList = torch.tensor([item.detach().numpy() for item in truList]);
print(truList.shape);
print("preList:");
print(preList);
plt.plot(np.array(truList),label="Ground Truth");
plt.plot(np.array(preList),label="Predictions");
plt.legend();
plt.show();