I’m using resnet-18 to infer test set. When I set the batch_size=10, I got average loss =0.96381098 as in this graph
.
But when I set batch_size=100, I got average loss=0.96381102 as you can see in this graph
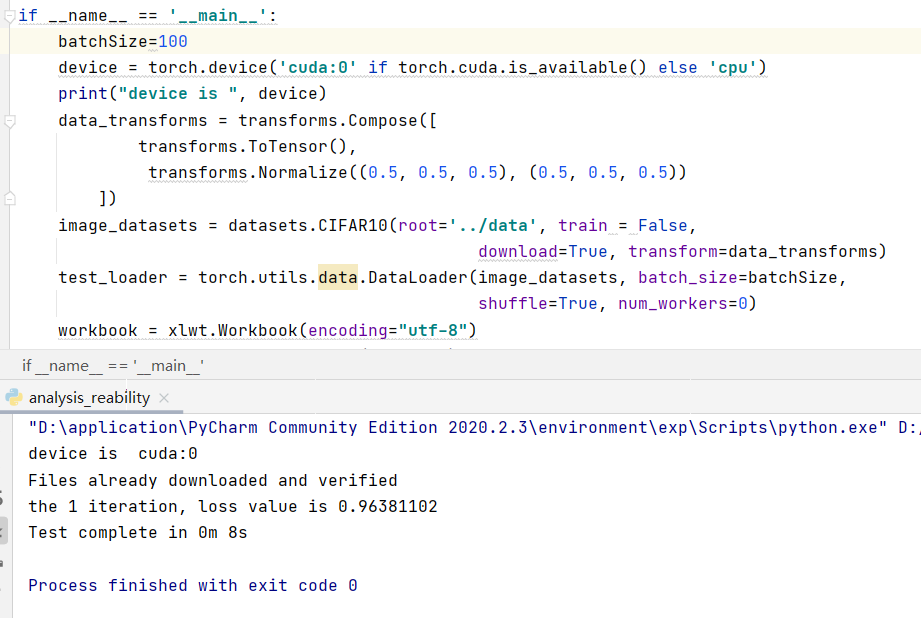
It’s very strange. My code is below.
import torch
from torchvision import datasets, transforms
import time
import torch.nn.functional as F
def testReability():
lossSum = 0.0
lossNumebr = 0
for i in range(1):
model = torch.load('resnet_18-cifar_10.pth')
model.to(device)
model.eval()
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
lossSum = lossSum + F.cross_entropy(output, target, reduction='sum').item()
lossNumebr = lossNumebr + len(test_loader) * batchSize
curLoss = lossSum / lossNumebr
print("the {} iteration, loss value is {:.8f}".format(i+1, curLoss))
if __name__ == '__main__':
batchSize=100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("device is ", device)
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
image_datasets = datasets.CIFAR10(root='../data', train = False,
download=True, transform=data_transforms)
test_loader = torch.utils.data.DataLoader(image_datasets, batch_size=batchSize,
shuffle=True, num_workers=0)
since = time.time()
testReability()
time_elapsed = time.time() - since
print('Test complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))