I tried to train Lprnet, an ocr network for Recognition license plates I used https://github.com/xuexingyu24/License_Plate_Detection_Pytorch/blob/master/LPRNet/LPRNet_Train.py to train this model
When I tested my validation set with batch size = 128 I got 95% accuracy rate but when I put batch size = 1 the model is very poor with only 73% accuracy rate which means that I predict single image with only 73% accuracy rate for me I was very surprised that I set model.eval () to ensure the model is in validation mode but it seems that the BN layer still affects my model Who has experience dealing with similar things can help me solve this problem Thank you
I found that other people have the same confusion as me. I tried some of the suggestions but they didn’t help me solve the problem, including
for child in model.children():
for ii in range(len(child)):
if type(child[ii]) == nn.BatchNorm2d:
child[ii].track_running_stats = False
I looked at the code for computing acc, and I found the evaluation a bit odd, in these lines: https://github.com/xuexingyu24/License_Plate_Detection_Pytorch/blob/master/LPRNet/Evaluation.py#L89-L96
If you can print some values for a single batch (use break to get out of the loop after one single iteration and avoid printing too much) and compare them across different batch-sizes. Then, you may see some weird or unexpected things happen when you change the batch-size.
Yes, the left side of this picture is the result when batch size = 1, and the right side is the result when batch size = 128. It can be found that when batch size = 1, the model will always predict one more bit in front. In fact, I found that when the same picture (batch size = 1) and this picture and other 127 pictures (batch size = 128) forward results are different, I think it may be that the BN layer parameters are not fixed, but I used model.eval ()
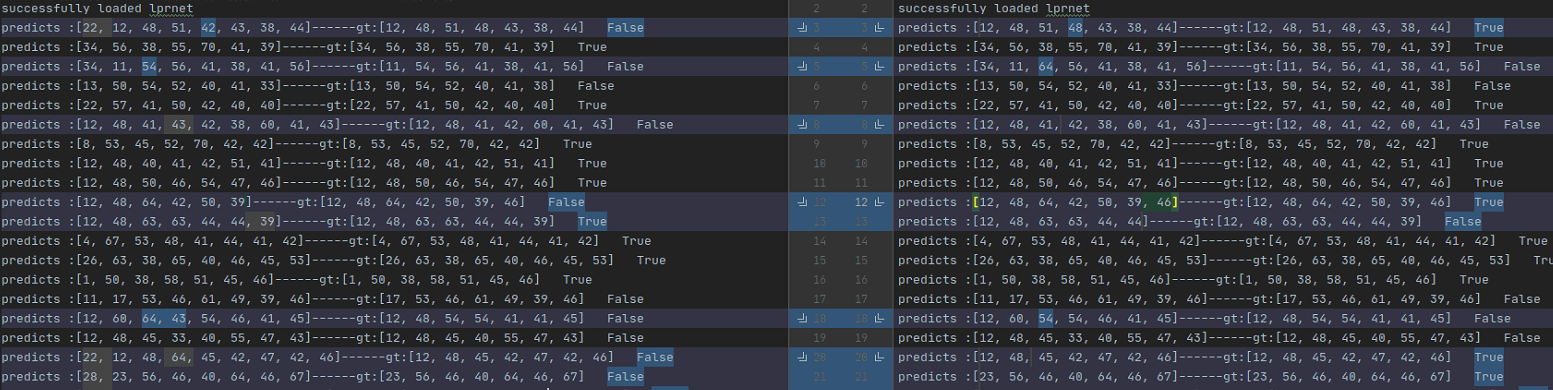
This problem has been bothering me for more than a day, who has encountered similar problems can help me .Thanks
bro, here are my suggestions:
firstly you should post this question to github repo instead of here…
secondly…you can try to write the evaluation dataloader by your own…and see if it works
you spend maybe 2 days to debug but maybe if you use 10min re-write the dataloader the problem solved.
Hi to everyone,
I have a question related to training and validation datasets. I have different value between training loss and validation loss for the same datasets (training = validation), I think that it’s not normal behavior.
Thanks for your answer.
Similar issue, my accuracy increases when I increase my batch size form 1 to 16. Any updates on this issue ?
Thanks.
In case you are seeing a bad validation performance when using a training batch size of 1: this could happen, if the running stats are not representing the underlying dataset stats and a known limitation of batchnorm layers. You could try to change the momentum to smooth the updates and also might want to read e.g. the GroupNorm paper which also explains these limitations.