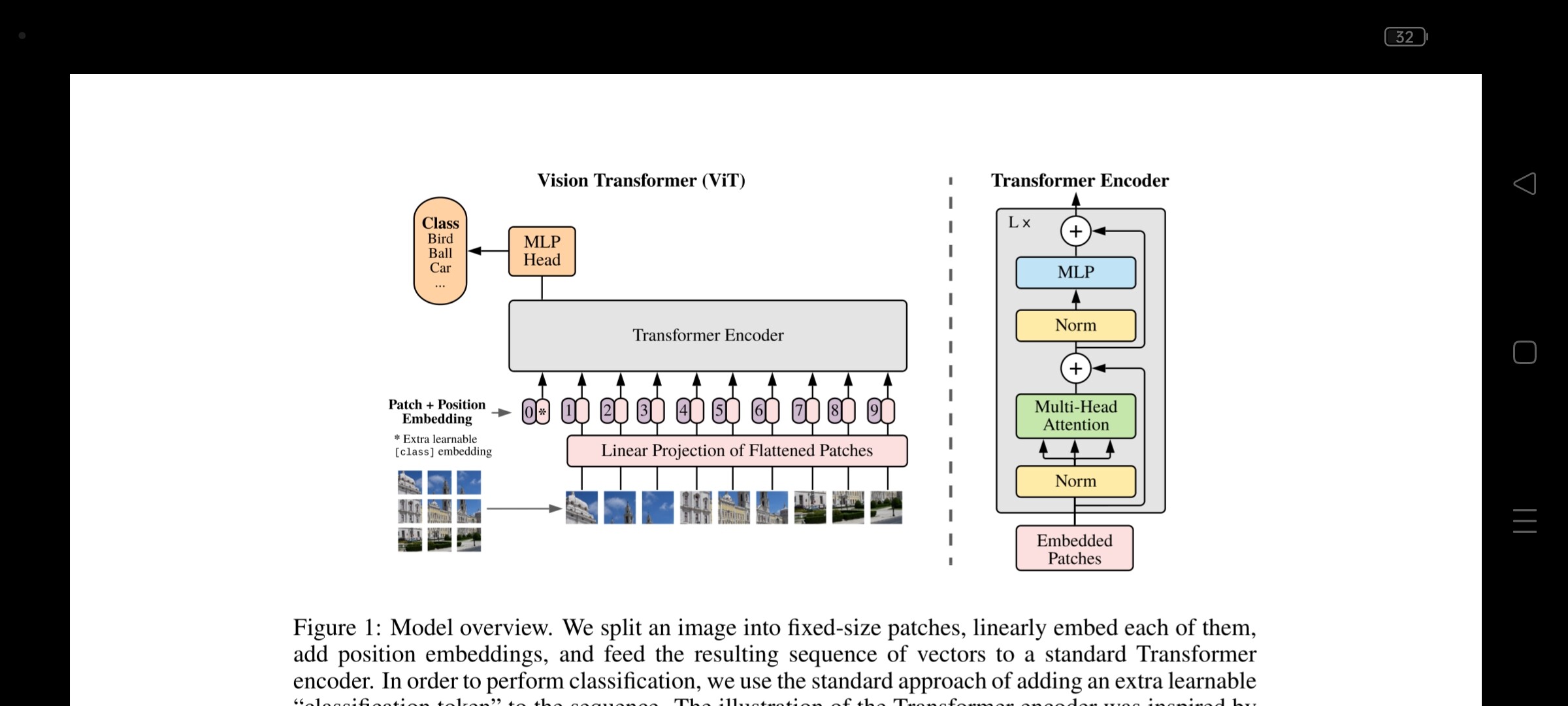
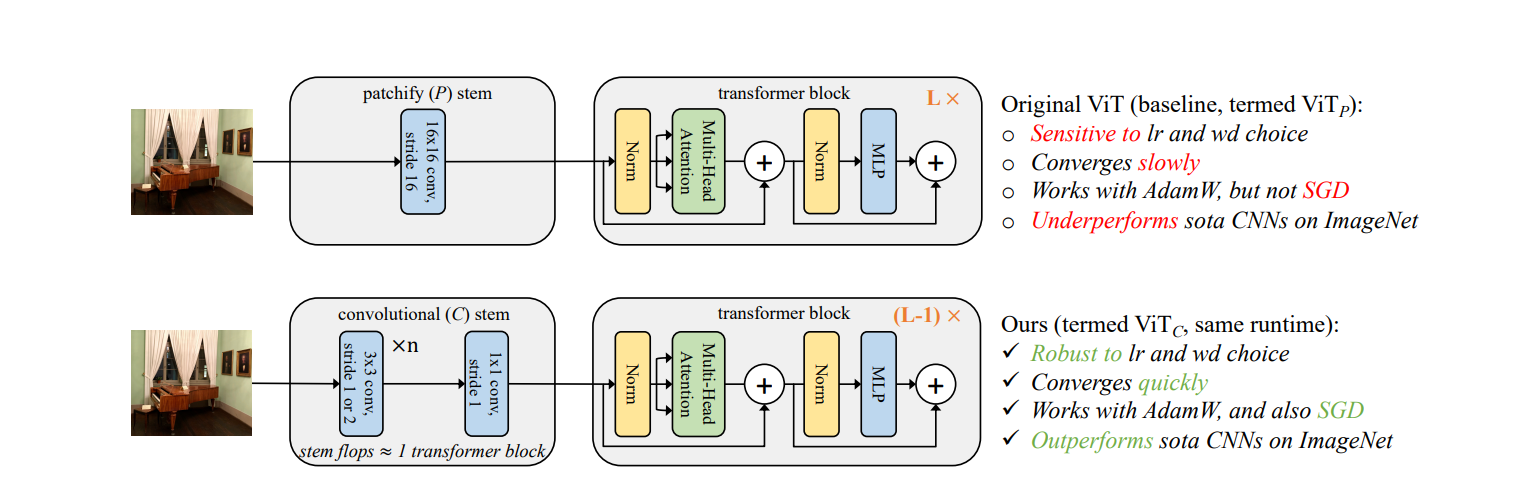
Hi there.
In Pytorch implementation of ViT, Conv2d is used over regular Patchify. in other words, researchers in An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale proposed framework which receives image in a number of pieces and processes it based on self-attention mechanism. but in Pytorch version, Conv2d is used instead of that.
VisionTransformer Class:
def _process_input(self, x: torch.Tensor) -> torch.Tensor:
n, c, h, w = x.shape
p = self.patch_size
torch._assert(h == self.image_size, f"Wrong image height! Expected {self.image_size} but got {h}!")
torch._assert(w == self.image_size, f"Wrong image width! Expected {self.image_size} but got {w}!")
n_h = h // p
n_w = w // p
# (n, c, h, w) -> (n, hidden_dim, n_h, n_w)
x = self.conv_proj(x)
# (n, hidden_dim, n_h, n_w) -> (n, hidden_dim, (n_h * n_w))
x = x.reshape(n, self.hidden_dim, n_h * n_w)
# (n, hidden_dim, (n_h * n_w)) -> (n, (n_h * n_w), hidden_dim)
# The self attention layer expects inputs in the format (N, S, E)
# where S is the source sequence length, N is the batch size, E is the
# embedding dimension
x = x.permute(0, 2, 1)
return x
def forward(self, x: torch.Tensor):
# Reshape and permute the input tensor
x = self._process_input(x)
n = x.shape[0]
# Expand the class token to the full batch
batch_class_token = self.class_token.expand(n, -1, -1)
x = torch.cat([batch_class_token, x], dim=1)
x = self.encoder(x)
# Classifier "token" as used by standard language architectures
x = x[:, 0]
x = self.heads(x)
return x
Can anyone explain for me why Conv2d is used? why not regular Patchify?!
Thanks.