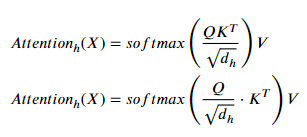As the title describes. I just compared the code of transformers from hugging face’s Bert and torch.nn.Transformer, directly from the code I found in my site-packages. Specifically, I’m looking for the part of dividing attention score before softmax. Most paper on transformer mentioned this:
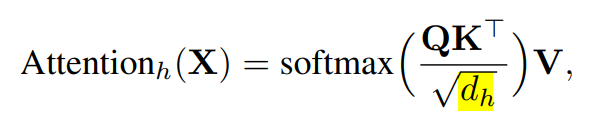
In hugging face’s Bert, I believe it is this line of code, which implement this quite right.
I believe the closest thing in PyTorch is this line, which is actually dividing query, not the result of dot product.
I’d like to know if they’re really equivalent? Wouldn’t that change the amount of backpropagation into Wq and Qk?
I know training transformer from scratch is hard. I’m having trouble training torch.nn.Transformer from scratch in a recent project. But could this be a reason why the loss won’t go down?