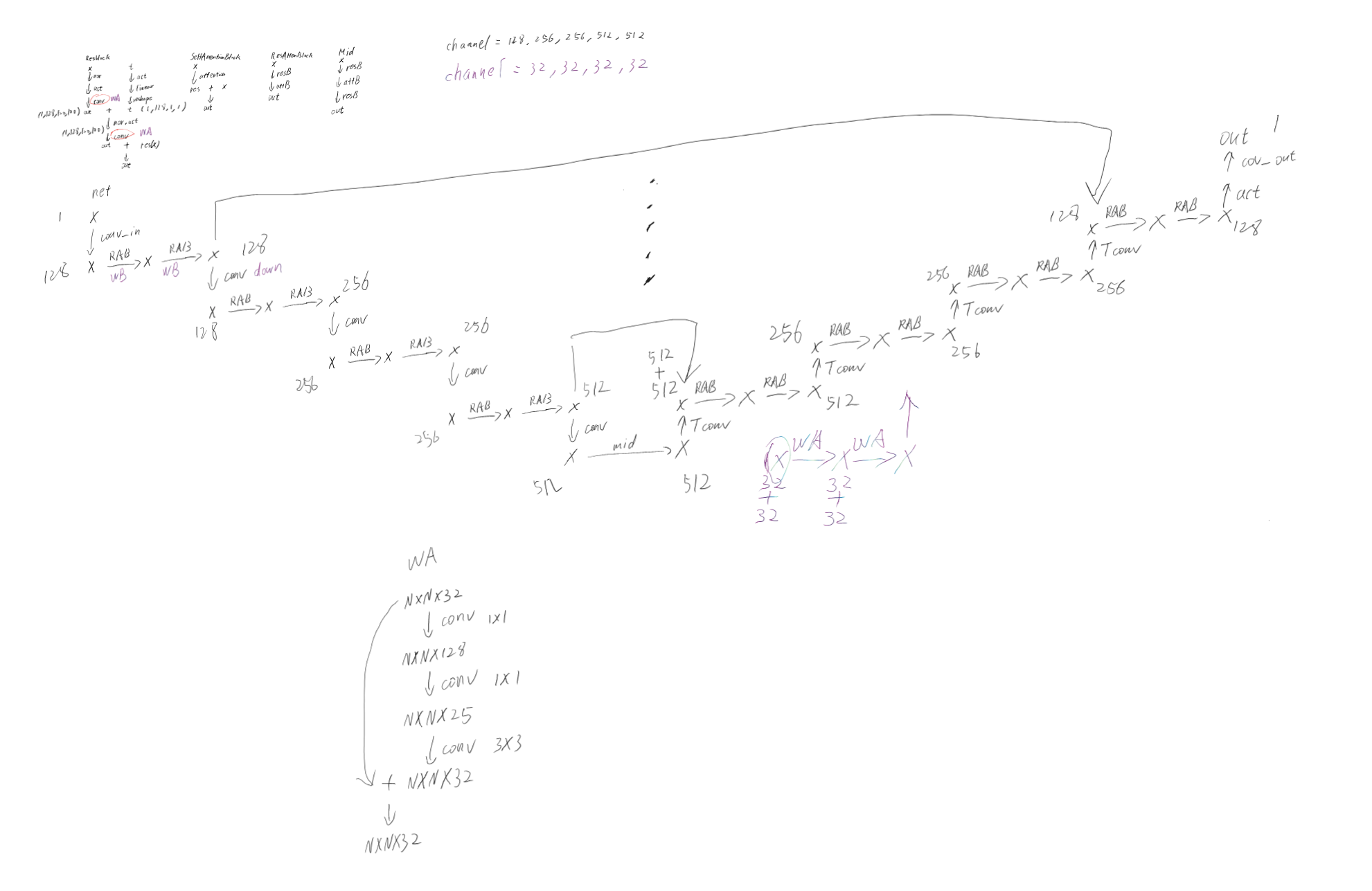
At the beginning, I used the architecture of U-Net+ residual +selfattention, which is the basic model of ddip (four layers of downsampling, each layer outputs the image of the feature dimension [128,256,256,512], with an intermediate layer, and the total parameter size is about 600mb. During the sampling process, I input an image [1,1900,1900] with less than 40Gb of video memory. (Black font as shown)
Later, I changed the basic convolutional layers (resblocks) of encoder and decoder into three convolutional layers (wa), three layers of downsampling, the average output feature dimension of each layer is 32, and the total model size is about 7mb. During the sampling process I also entered an image [1,1900,1900], indicating that I needed 180Gb of video memory.
I want to know why this is and how to solve this problem?
Forward activations will most likely use the large amount of memory as explained here.