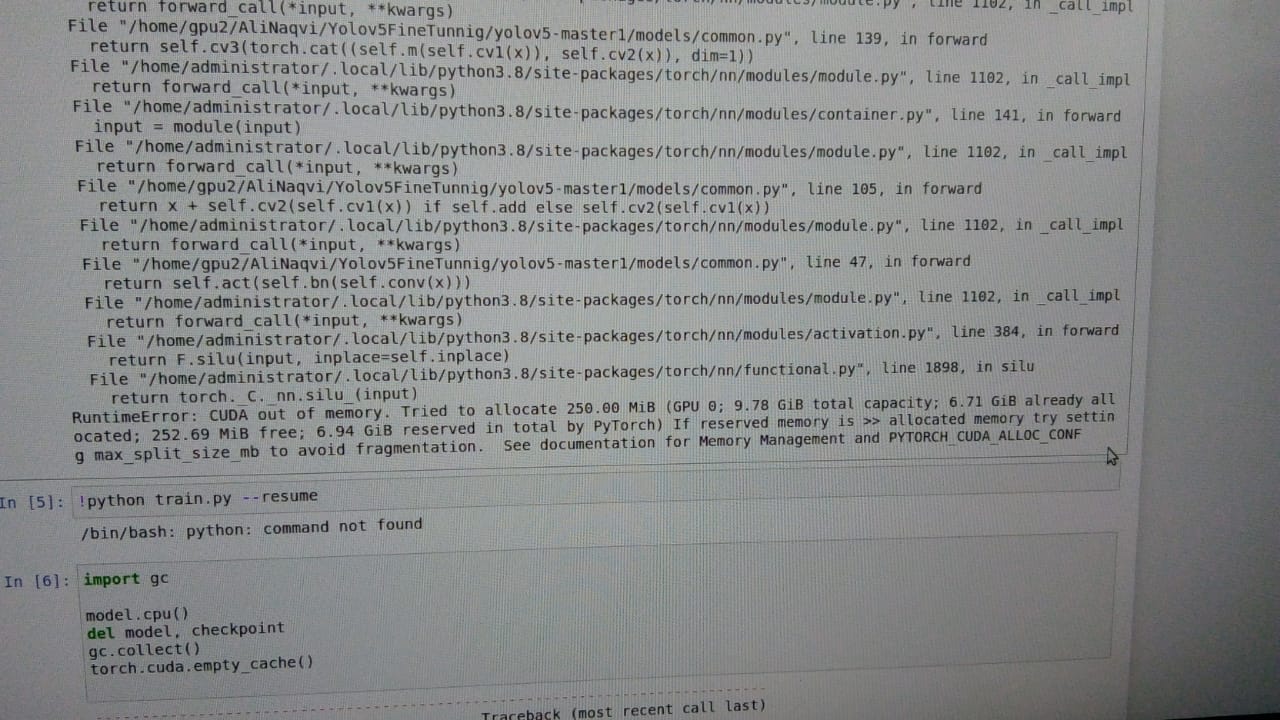
Why did pytorch run through the code before, when I run it again this time, I reminded: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 6.00 GiB total capacity; 353.72 MiB already allocated; 3.86 GiB free; 396.00 MiB reserved in total by PyTorch)
Could you check, if the previous script crashed and if zombie processes might be using the device memory? If so, kill them, and rerun the script.
Hi hope you are well.
I’m also getting a similar kind of error.
First I finetuned Yolov5 on custom data.
After obtaining best I tried to refine model on those best weights but with different image size.
but now i can’t run model even with small batch size.
And I can’t run any other mode like detection transformer on machine
I tried to emtpy cache as suggested but all in vain
I tried to run code on different machine with same GPU RTX 3080 and and Vram 10GB
Any idea how can i fix this error.
I guess other (dead) processes might use the device memory, so check them via nvidia-smi and/or ps aux and kill them if needed.
i can’t see any heavy projects ruuning
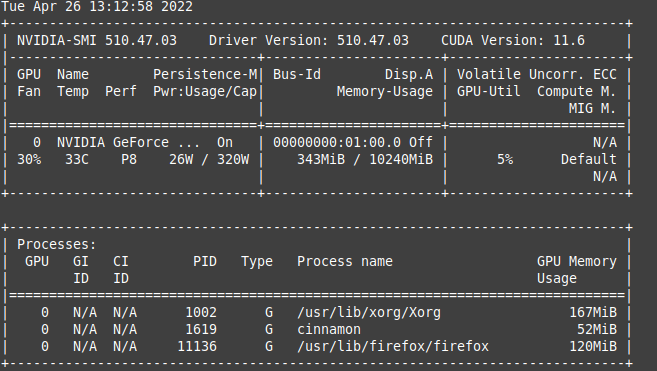
Why 7.18 GiB reserved in total by PyTorch??
The memory usage depends on the actual model architecture as well as the input shapes besides some other requirements for e.g. workspaces for specific kernels etc.
E.g. you would have to store all model parameters, buffers, input tensors, forward activations, gradients, optimizer states (if used). What are your expectations and how did you estimate the memory requirement?