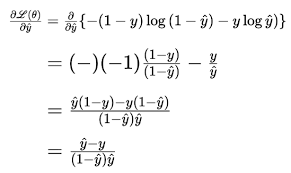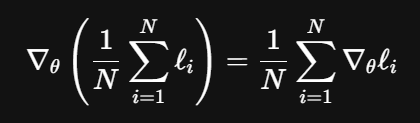I built a vanilla GRU net to resolve a binary classification problem, and train it with a batch size greater than 1.
Let’s say my NN model got a correct result with sample-0, and got a incorrect result with sample-1 in a same batch, when training.
When torch.nn.BCELoss(for example) was used to calculate the loss, it simply added all of losses into a scalar(not a matrix), and then this scalar loss(sum or mean) was propagated backward all neurons of the net, and every weights would be adjusted according to this scalar.
But in my view, the correct classifying behavior should be encouraged, and the incorrect behavior should be punished, instead of blindly adjust all the weights according to a single loss value.
What magic does PyTorch do in the background?
I’m a freshman in NN and DL. Thanks for your patience!
The loss of a mini-batch is an estimate of the expectation of the loss with respect to the true data-generating function. In this manner, mini-batches of larger size provide a more accurate (in general) estimate of true gradient descent, which would take the entire dataset into account for each step. Clearly its a pretty inefficient computation to take the entire dataset, hence the mini-batch approach. It isn’t “blindly” adjusting the weights according to a single value, its taking samples from the population and seeing in what overall direction would minimize the loss. This is more of a math/optimization question than a PyTorch specific question. PyTorch takes the mean of the loss per batch element, not the sum.
You can experiment with a single batch element and you will see that it might take more epochs to converge, and worse performance on the test set. Gradients from a single example are noisy. Statistics tends to reward more samples, and I would argue that deep learning is a kind of applied statistics. The relationship between batch size, learning rate, and optimizer is unfortunately a kind of trial and error according to my experience. There are papers written giving optimal choices for simple/distinct scenarios, but it’s hard to generalize concretely. For classification I would say try to use the biggest batch size you can. Also in your example the correct classifying behavior would be rewarded with a small gradient, while the incorrect prediction would be punished with a large gradient, in terms of the norm.
Indeed I have experimented with a single sample each batch (i.e. batch size = 1), and I got a similar training result.
Of course it need much more time to run through all the data, because it can not take advantage of the parallelism of GPU.
As to the speed of convergence you mentioned, I have not observed a obvious difference comparing to a larger batch size.
I have this doubt because the loss of a batch is a scalar value, it can NOT be a flag to point out which classifying(predicting) is good, and which classifying is bad.
For example, there is only neuron in our net, that has a positive derivation of the input. If a classifying get correct result with sample-0, the weight in this neuron should be enlarged(or left unchanged at least).
But at same time, in same batch it got a incorrect result with sample-1, that would result a larger loss value. Then the weight would be decreased regardless whether or not the classifying results were correct. Is this not we wanted?
Can you give me an example of your network, is it basically just logistic regression (i.e. a linear layer with n inputs, 1 output, followed by a sigmoid operation trained with binary cross entropy)?
saw this, ik it’s too late to answer the original guy who asked this , but imma do it for anyone who stumbles upon this.
in the question , @evilroach is confusing 2 different things , the scalar value of the loss at the end (0 in this case) and the loss as in a variable, not a constant .
let me clarify , the 0 output loss at the end of the network is what the network takes into account in backward prop , it’s more like 0=C=loss(ytrue,ypedicted) so we don’t d0/dweights since that would be nonesense ,we do dC/dweights . which is basically what derivative means , here’s an example:
the way torch and all deeplearning frameworks (that i know of) do it is not by traditional derivative (the symbolic derivative thought in high schools), but rather with autograd which is faster & more precise .have a look at the torch tensor.grad and experiment with it, and have a look at torch’s documentation in autograd part , it’s very interesting!!
Aha! After 2 years, I found that myself confusion between “the losses to be propagated backward” and “the average loss of a batch of predictions”.
The former is used to update weights, while the latter is only used to show the quality(metrics) of predictions in trainning progress or at a evaluation.
The former is a tensor with a shape same as Y(NOT a scalar), and contains all losses of each pair of [predict vs truth] in a batch.
Every elements of it represents one single loss(scalar) of a pair of [predict vs truth] respectively, NO aggregation on it!!!
So certainly, the backward propagations make sense!
As to the latter, is a scalar, only for viewing.
I think that I confused these two things that time.
Thank everybody helped me on the road to learn things!!!
Hah!
Bro, You’re kind of right. Firstly, The losses of a mini-batch were aggregated indeed. Secondly, the loss value to plot was the mean of a epoch (not batch) in a statistical view. While, “aggregated” gradient=the total contribution of single loss in mini-batch