Numpy uses NHWC, pytorch uses NCHW, all the conversion seems a bit confusing at times, why does Pytorch use NCHW at the very beginning?
I think it was the default format in LuaTorch and I don’t know, why this format was preferred over NHWC.
However, note that PyTorch has now experimental channels-last support. By using this, you would still create and index the tensors as NCHW to guarantee backwards compatibility.
Hi,
About the ordering, I think NCHW is much more intuitive rather than latter choice. It is like going from high level to low level view (batch_size > patch_size > channel_size).
PyTorch uses a Storage for each tensor that follows a particular layout. As PyTorch uses strided layout for mapping logical view to the physical location of data in the memory, there should not be any difference in performance as it is only a swap of channels in stride value. There are some information about this in a talk by @ezyang in his blog post PyTorch internals : Inside 245-5D).
In a part of it, this image has been provided and a caption that says: By the way, we’re interested in making this picture not true; instead of having a separate concept of storage, just define a view to be a tensor that is backed by a base tensor. This is a little more complicated, but it has the benefit that contiguous tensors get a much more direct representation without the Storage indirection. A change like this would make PyTorch’s internal representation a bit more like Numpy’s.
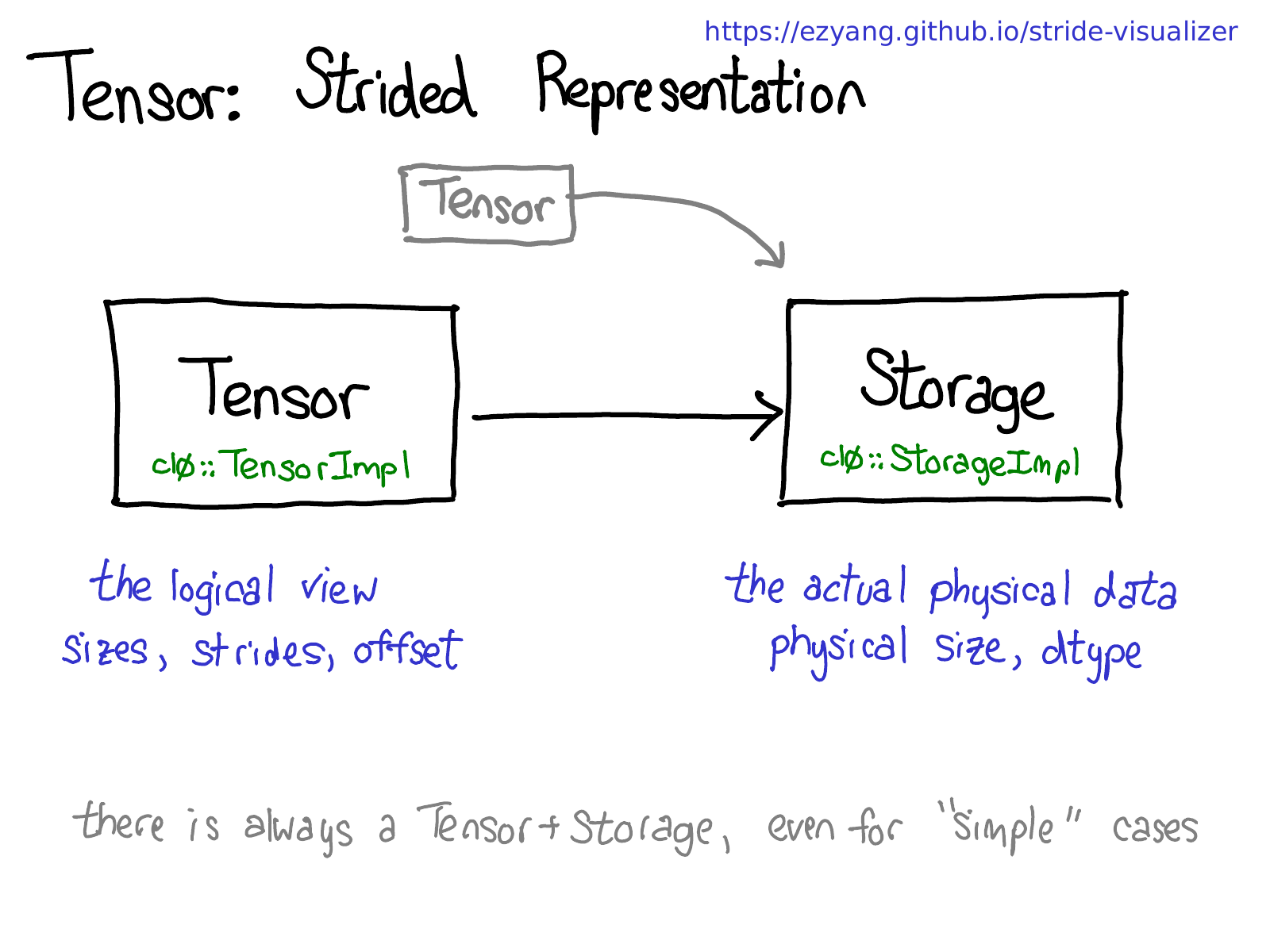
But in the link you have provided, it has been shown that there is a perf gain in almost all prominent architectures. What could be the possible explanation for this?
Bests
IIRC, NHWC allows you much better implementation for convolution layers that gives a nice boost in perf (because the value for all channels is accessed for every pixel, so data locality is much better in that format).
The problem is that batchnorm-like layer are so much faster in NCHW, that vision models nowadays do not perform that much better in NHWC (for these layers, you reduce over the HW dimensions. And so having C last breaks the data locality).
But for the original question: I would agree with @ptrblck: for historical reasons mostly and because there is no clear reason that the other format is better in general (at least not worth rewriting all the TH/THC libraries!).
As @albanD pointed out, the memory access pattern is beneficial in NHWC for (some) convolution implementations. Also, TensorCores natively use NHWC tensors, so you are saving a permutation inside the cudnn kernels.
The last slide in this presentation shows some numbers.
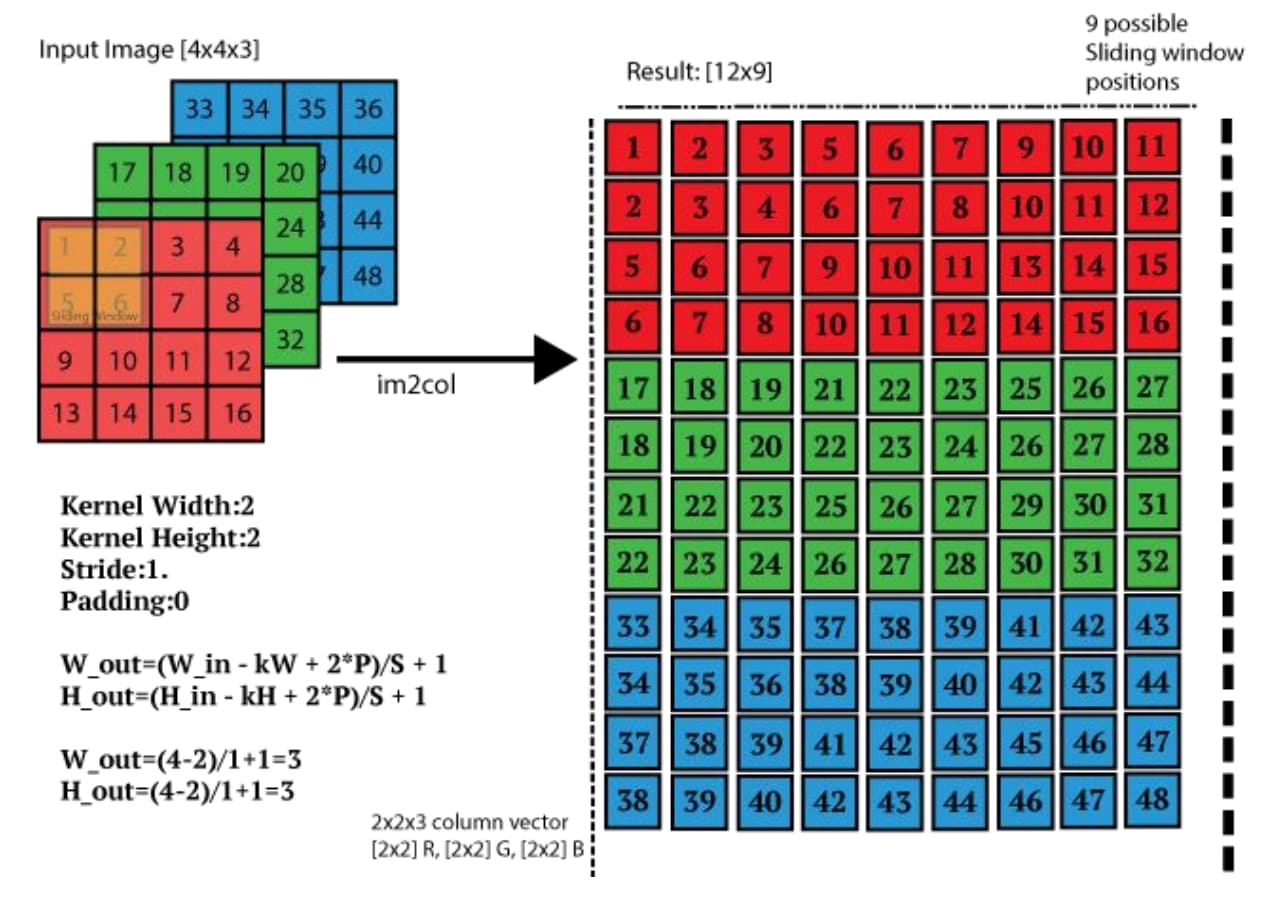
Your reference image is one example, another possible layout after im2col looks like (only show 1st column):
1
17
33
2
18
34
5
21
37
6
22
38
as long as filter has the same layout after im2col.
With cuDnn’s terms, this is called the ‘CRS’ dimension. (C: Channel, R: kernel height, S: kernel width)