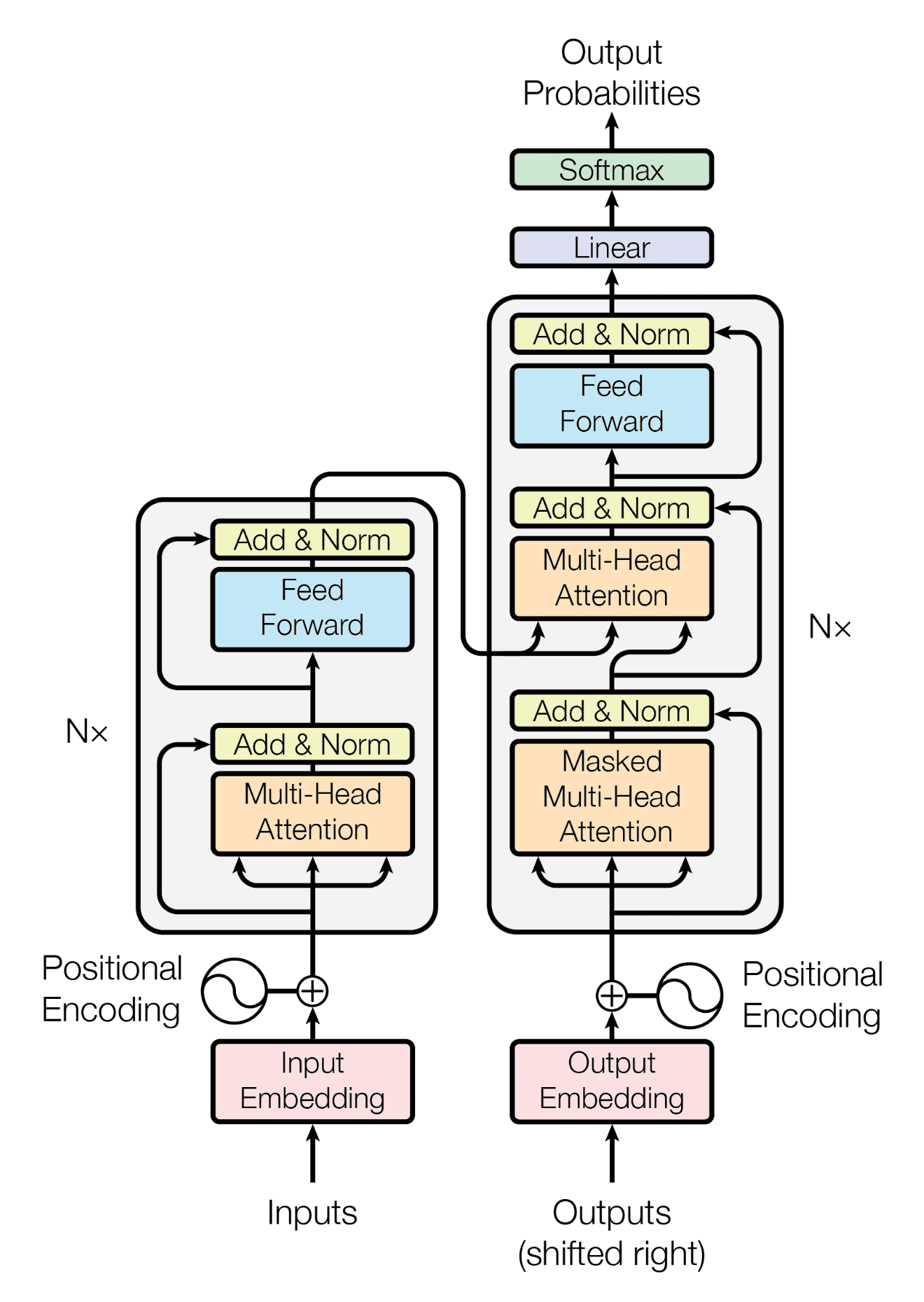
In the code of torch.nn.Transformer (torch.nn.modules.transformer — PyTorch 2.1 documentation), the encoder part is implemented as follows:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first, norm_first,
**factory_kwargs)
encoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
From torch.nn.TransformerEncoder (torch.nn.modules.transformer — PyTorch 2.1 documentation) 's code we can see the output is passed through the above LayerNorm layer:
if self.norm is not None:
output = self.norm(output)
return output
My questions is: why do we need to add another LayerNorm, considering we have LayerNorm layers applied to self-attention and FFNN respectively already? What’s the benefit? Is it necessary?
torch.nn.TransformerEncoderLayer (torch.nn.modules.transformer — PyTorch 2.1 documentation) 's output:
else:
x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask, is_causal=is_causal))
x = self.norm2(x + self._ff_block(x))
return x