Can you please post some code that reproduces the error?
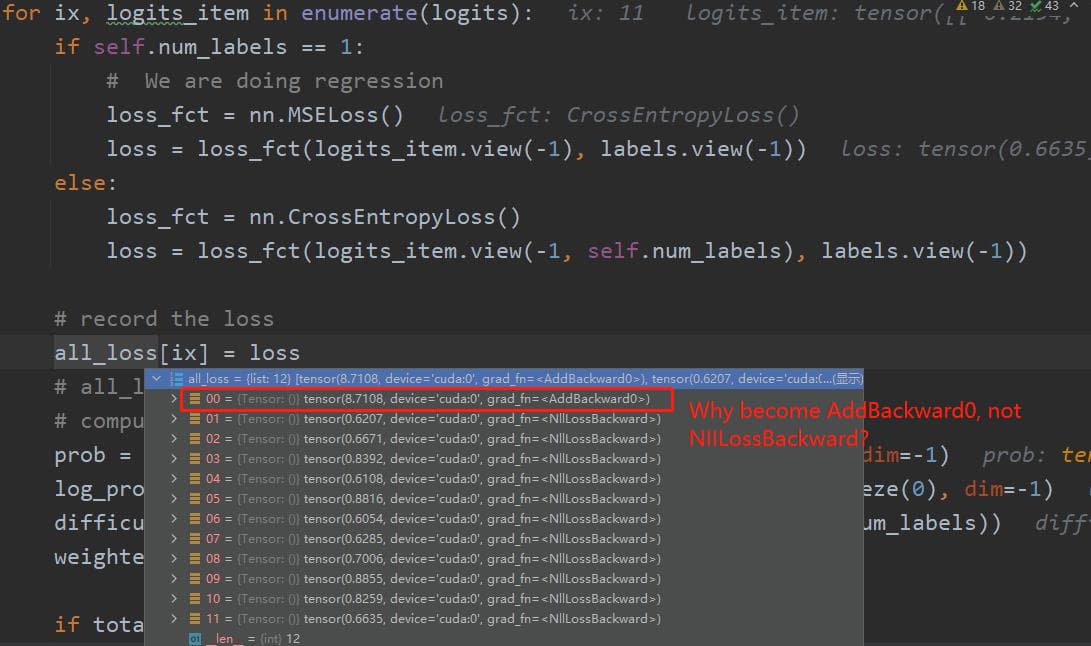
From what I can understand as of now, logits contains sets of predictions as its elements (essentially arrays of set of predictions - like prediction sets from various inference runs).
And you are trying to record the loss from each set of predictions in all_loss. That to say, for 5 inferential runs, all_loss will have 5 values of losses. Is that it?
Generally, a common reason for grad accumulation is when one misses torch.no_grad, but here it’s happening just for the first element so not sure, I’ll have a look at more code first.
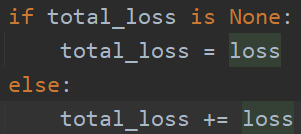
Thank you. I have solved this problem yesterday. The above screenshot just obscures the key place, that is, total_loss += loss ( as you can see in the images below) makes the all_loss and total_loss point to the loss, and there is a value binding, so that the sum of the total_loss acts on the first element of the all_loss.
I see.
According to this code, it’s happening because of the inplace operation total_loss += loss.
Changing it to total_loss = total_loss + loss should solve the accumulation error.
Did you try anything else to solve this?
You’re great!My solution is to sum up outside the for loop, but your solution is more elegant.
Ok, nice to know it works. you could mark it as the solution that’ll help anyone reading this thread in future.