Hello!
As you can see predicted curves are zeroed at the places where target-curves have negative values.
So the question:
Why does the neural network predict (orange) only positive values, when targets (blue) in the training dataset contain negative values as well? What could possible reasons be?
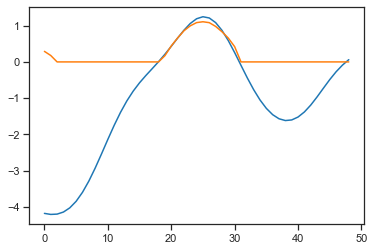
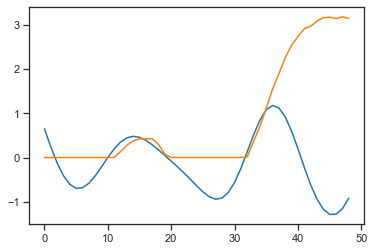
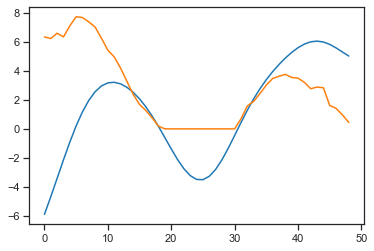
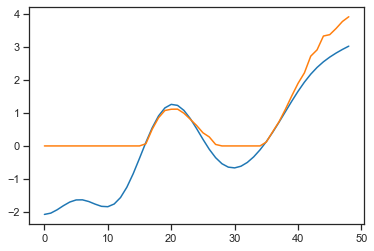
Can you provide some code?
Do you have a ReLU layer at the end that would zero out any negative values?
1 Like
I am happy, but the code is huge, and I dont have any idea where this behaviour may come from.
Maybe I can describe main features.
It is a convolutional neural network with
- 1 conv-layer (7 filters 11x11, stride and paddings are all equal to 5, no maxpools nor batchnorms) and
- 2 fully-connected layers (with the second layer being an output layer). I apply batchnorm to the first FC-layer.
I use ReLU activation functions everywhere.
The loss function is defined by torch.nn.MSELoss(), i.e. mean-squared-error loss function.
I use Adam optimization method.
Please, let me know if there is anything else that needs to be mentioned.
I tested my code on the MNIST hand-written digits dataset, and it worked well (provided that loss is cross-entropy type loss and few other corrections to a classification problem).
I just saw your answer. Yes! That is probably it. I will try to use sigmoid function at the end.
A sigmoid function would not be any better since that would bound your answer to [0,1]. It seems that your output does not have a specific range so it may be better to use no activation function at the end in that case.
1 Like