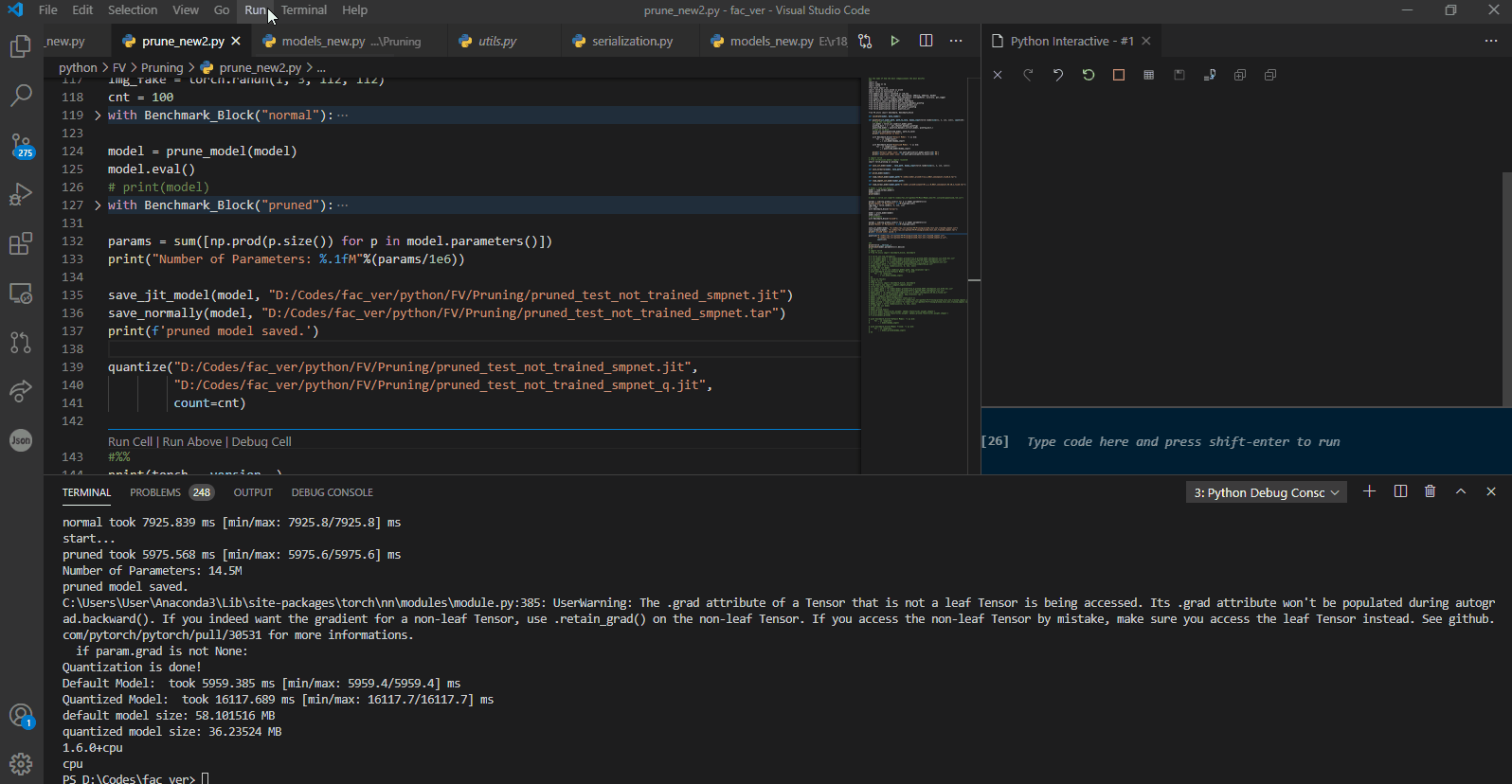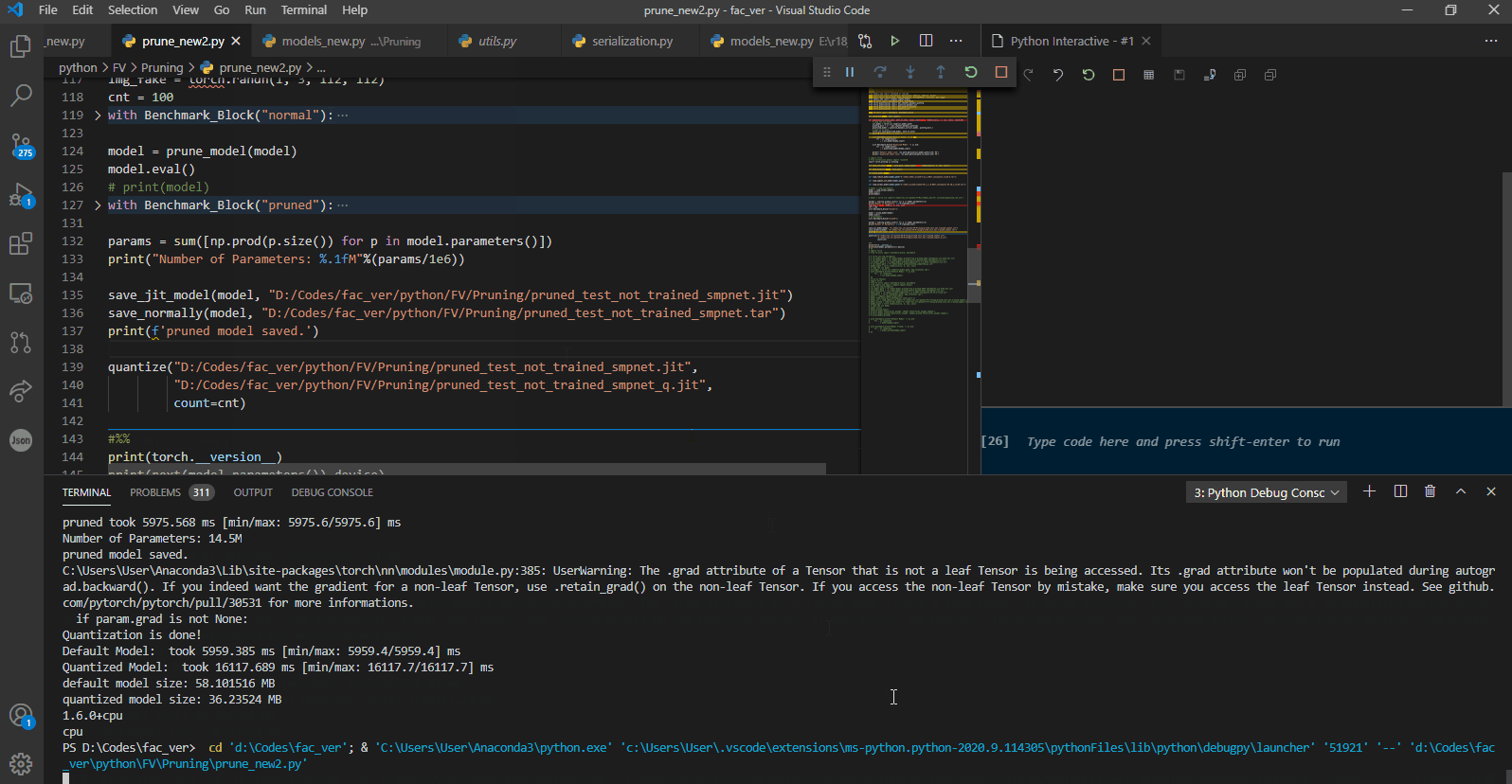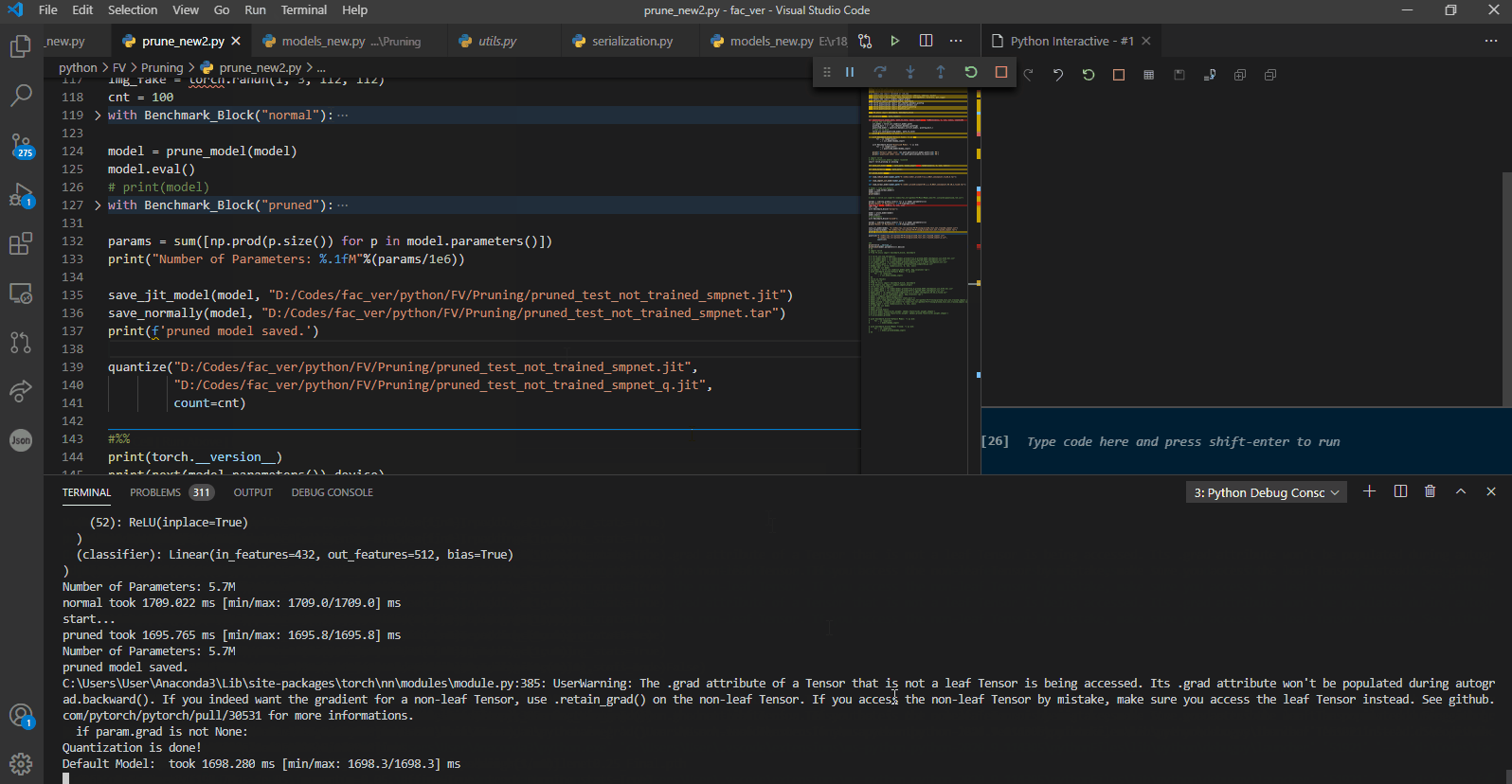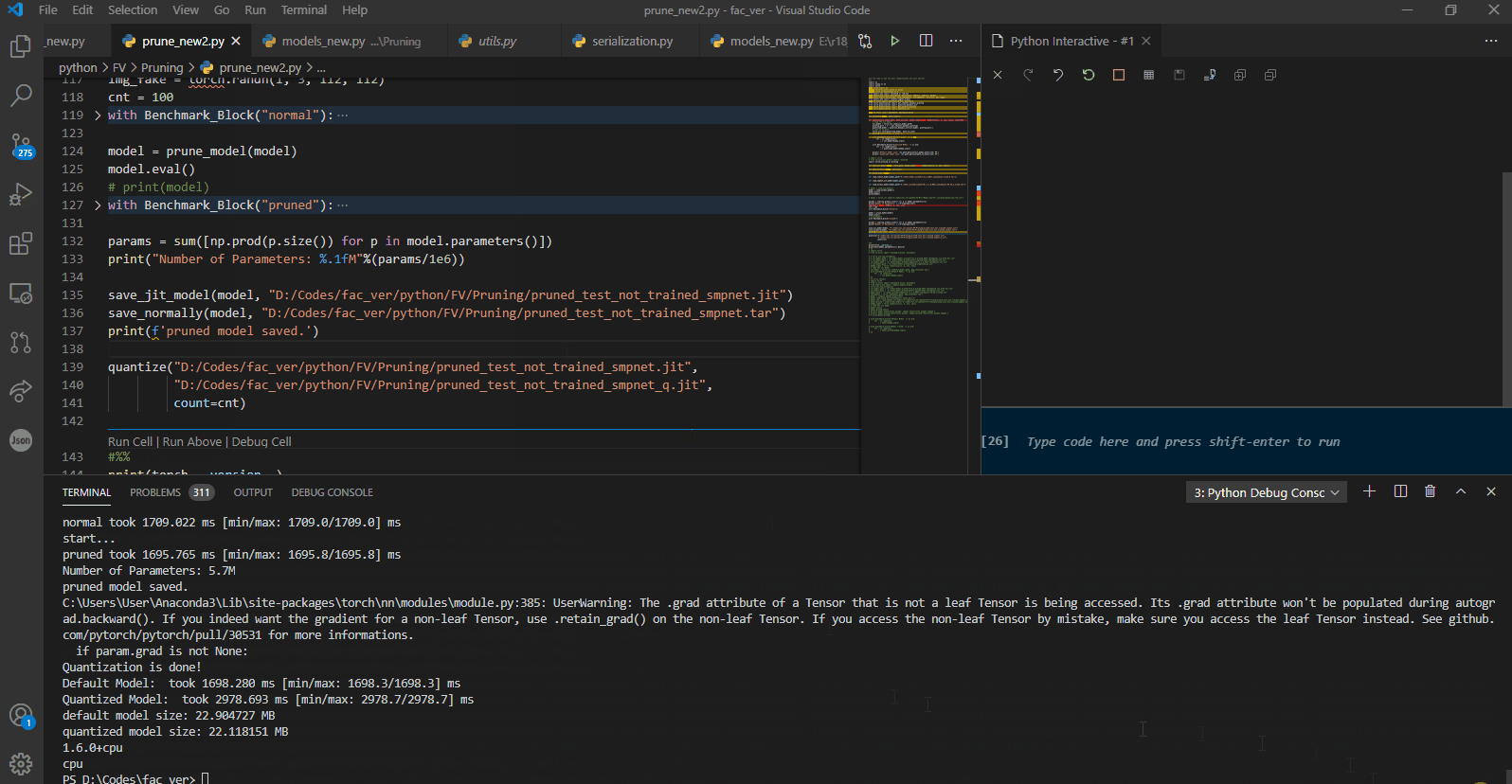
I have resnet18 model which I quantized using graph quantization, each forward pass on my system takes about 100 ms (on cpu) and its size shrunk from 85 to 45 MBs.
I then went on and poruned this model to 14.5M parameters from the initial 25M and its size shrunk from 85 to 58MB. I then went on and quantized the resulting model hoping for improvements.
but in fact I’m seeing dimnishing results. That is, I dont see what I expected in inference speed. instead of being better, the newer model simply is worse than the initial model (quantized from initial model)
Is this expected behavior?
Here are the two models for comparision :
and this is their runtime benchmark results :
pruned-quantized model :
1>[ RUN ] EmbedderModelForwardFixture.ModelEmbedderBench (10 runs, 10 iterations per run)
1>[ DONE ] EmbedderModelForwardFixture.ModelEmbedderBench (5778.116020 ms)
1>[ RUNS ] Average time: 577811.602 us (~26296.168 us)
1> Fastest time: 537246.562 us (-40565.040 us / -7.020 %)
1> Slowest time: 617859.662 us (+40048.060 us / +6.931 %)
1> Median time: 585275.362 us (1st quartile: 554311.262 us | 3rd quartile: 594753.362 us)
1>
1> Average performance: 1.73067 runs/s
1> Best performance: 1.86134 runs/s (+0.13067 runs/s / +7.55054 %)
1> Worst performance: 1.61849 runs/s (-0.11218 runs/s / -6.48174 %)
1> Median performance: 1.70860 runs/s (1st quartile: 1.80404 | 3rd quartile: 1.68137)
1>
1>[ITERATIONS] Average time: 57781.160 us (~2629.617 us)
1> Fastest time: 53724.656 us (-4056.504 us / -7.020 %)
1> Slowest time: 61785.966 us (+4004.806 us / +6.931 %)
1> Median time: 58527.536 us (1st quartile: 55431.126 us | 3rd quartile: 59475.336 us)
1>
1> Average performance: 17.30668 iterations/s
1> Best performance: 18.61343 iterations/s (+1.30675 iterations/s / +7.55054 %)
1> Worst performance: 16.18491 iterations/s (-1.12177 iterations/s / -6.48174 %)
1> Median performance: 17.08597 iterations/s (1st quartile: 18.04041 | 3rd quartile: 16.81369)
quantized from normal model (no pruning done beforehand) :
1>[ RUN ] EmbedderModelForwardFixture.ModelEmbedderBench (10 runs, 10 iterations per run)
1>[ DONE ] EmbedderModelForwardFixture.ModelEmbedderBench (5672.357520 ms)
1>[ RUNS ] Average time: 567235.752 us (~31674.053 us)
1> Fastest time: 530900.462 us (-36335.290 us / -6.406 %)
1> Slowest time: 640024.562 us (+72788.810 us / +12.832 %)
1> Median time: 561095.762 us (1st quartile: 548392.562 us | 3rd quartile: 577176.062 us)
1>
1> Average performance: 1.76294 runs/s
1> Best performance: 1.88359 runs/s (+0.12066 runs/s / +6.84409 %)
1> Worst performance: 1.56244 runs/s (-0.20050 runs/s / -11.37282 %)
1> Median performance: 1.78223 runs/s (1st quartile: 1.82351 | 3rd quartile: 1.73257)
1>
1>[ITERATIONS] Average time: 56723.575 us (~3167.405 us)
1> Fastest time: 53090.046 us (-3633.529 us / -6.406 %)
1> Slowest time: 64002.456 us (+7278.881 us / +12.832 %)
1> Median time: 56109.576 us (1st quartile: 54839.256 us | 3rd quartile: 57717.606 us)
1>
1> Average performance: 17.62935 iterations/s
1> Best performance: 18.83592 iterations/s (+1.20657 iterations/s / +6.84409 %)
1> Worst performance: 15.62440 iterations/s (-2.00495 iterations/s / -11.37282 %)
1> Median performance: 17.82227 iterations/s (1st quartile: 18.23511 | 3rd quartile: 17.32574)
Or to put it simply after 10 iterations:
r18_default : 805.72 ms (mean)
quantized_model : 560 ms (mean)
r18_pruned : 7,466.78 ms
pruned_then_quantized: 578 ms (mean)
Not only the second model is not faster, its worse, its become slower!
You can also see that the pruned model is extremely slow! 10x slower than the default model!
Note:
in case it matters, training (pruning, and finetuning the model) is done using pytorch 1.5.1 and the final graph quantization is done in windows using pytorch 1.6
Note2:
This is being tested and evaluted using libtorch(1.6) on windows 10 machine.
I’d greatly appreciate any kind of feedback on this.
Thank you all in advance