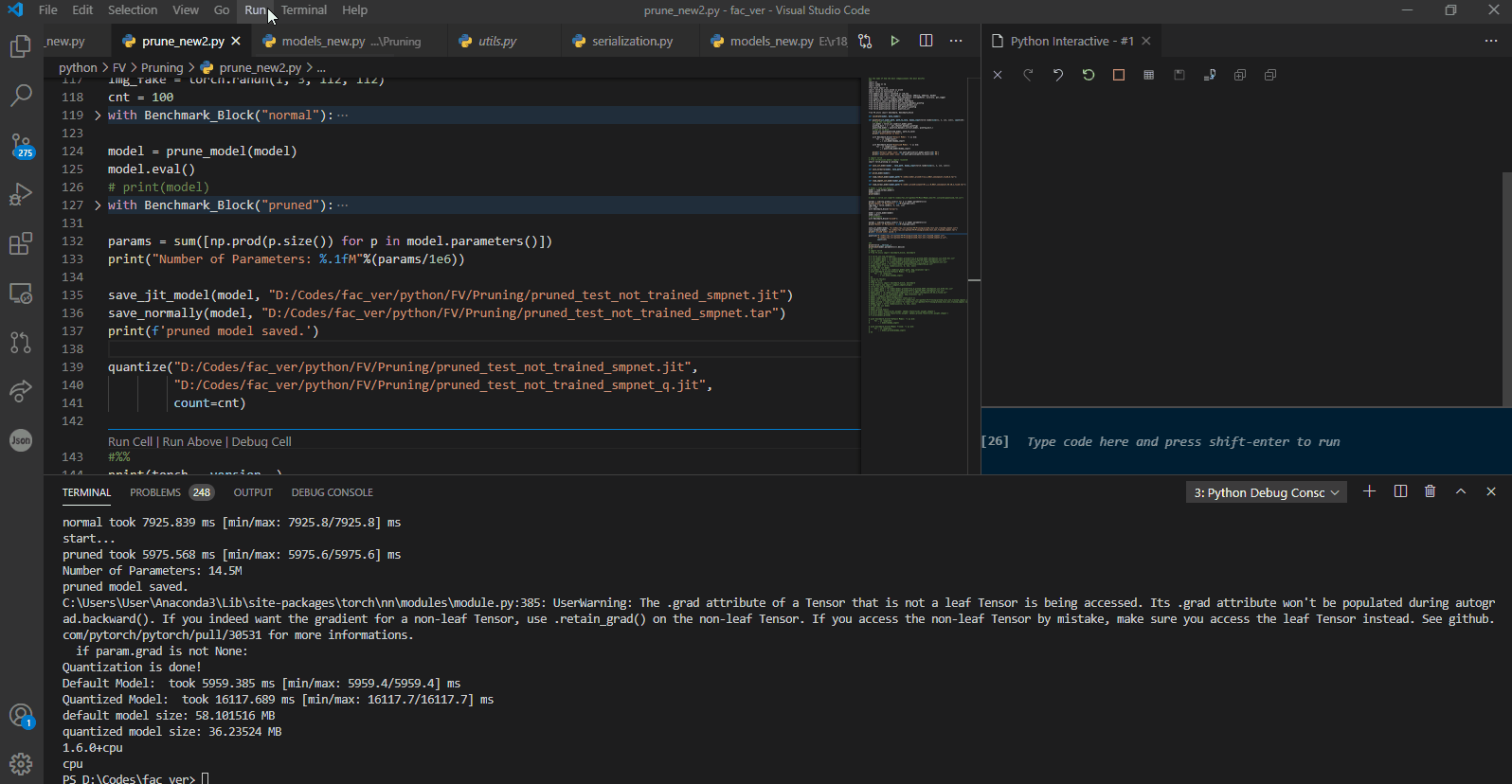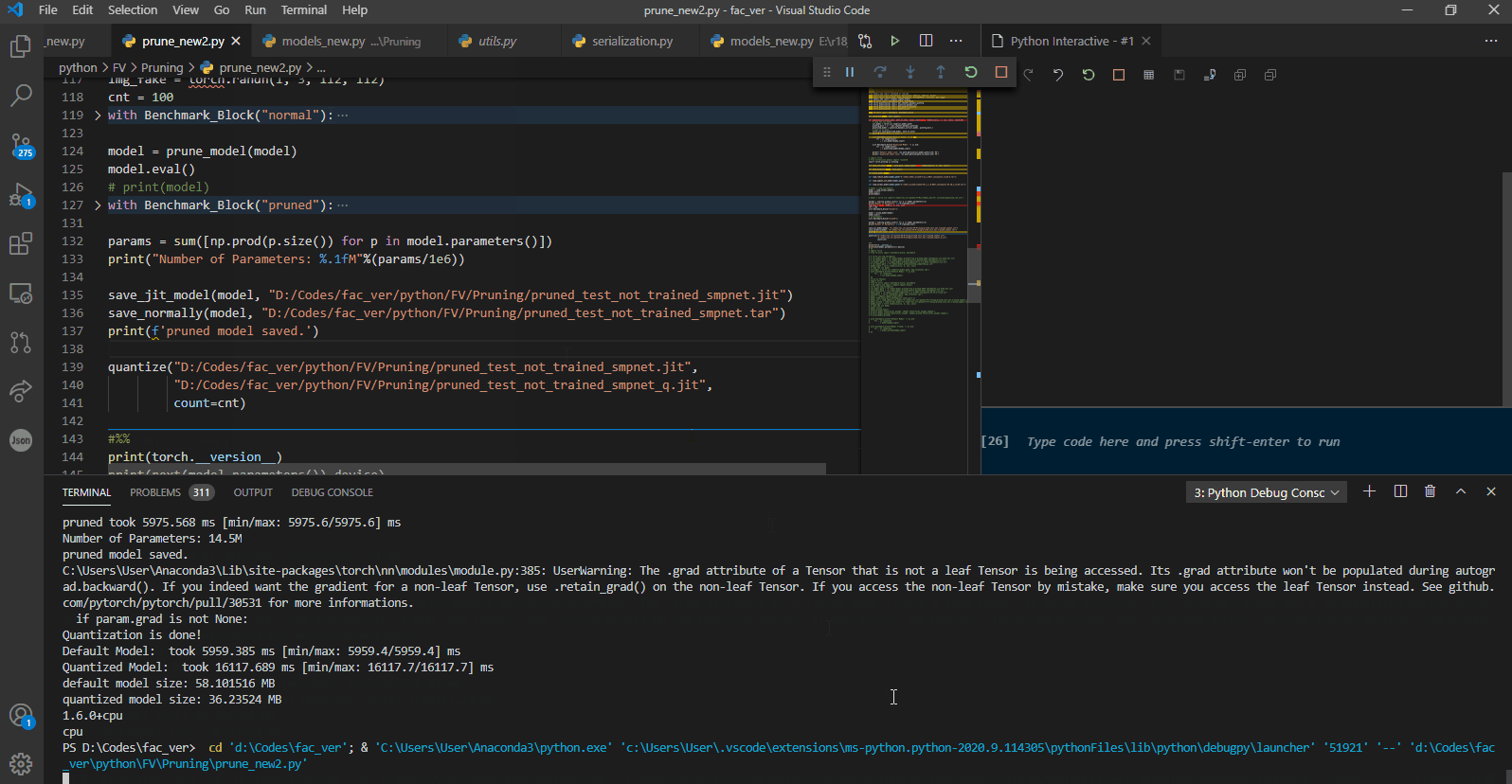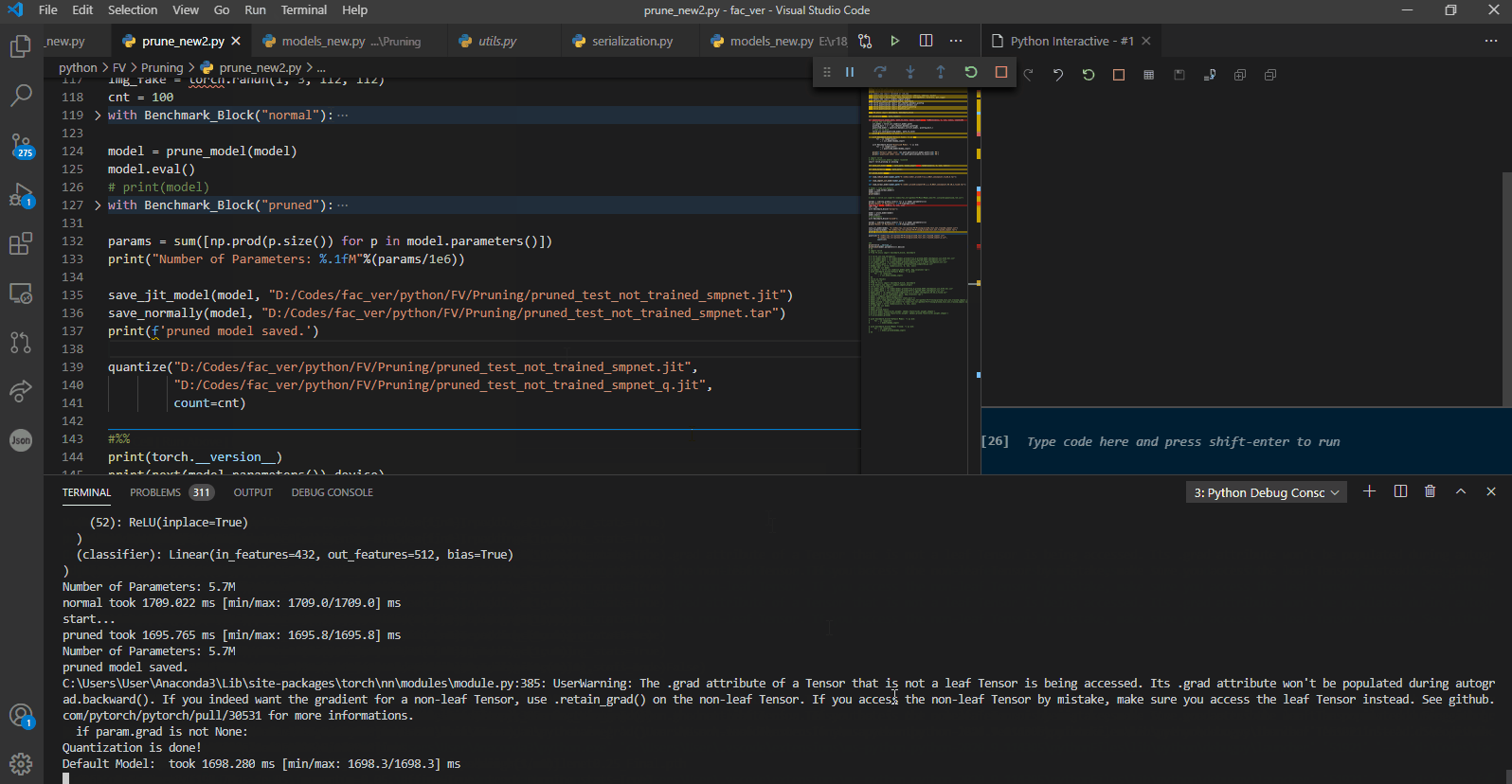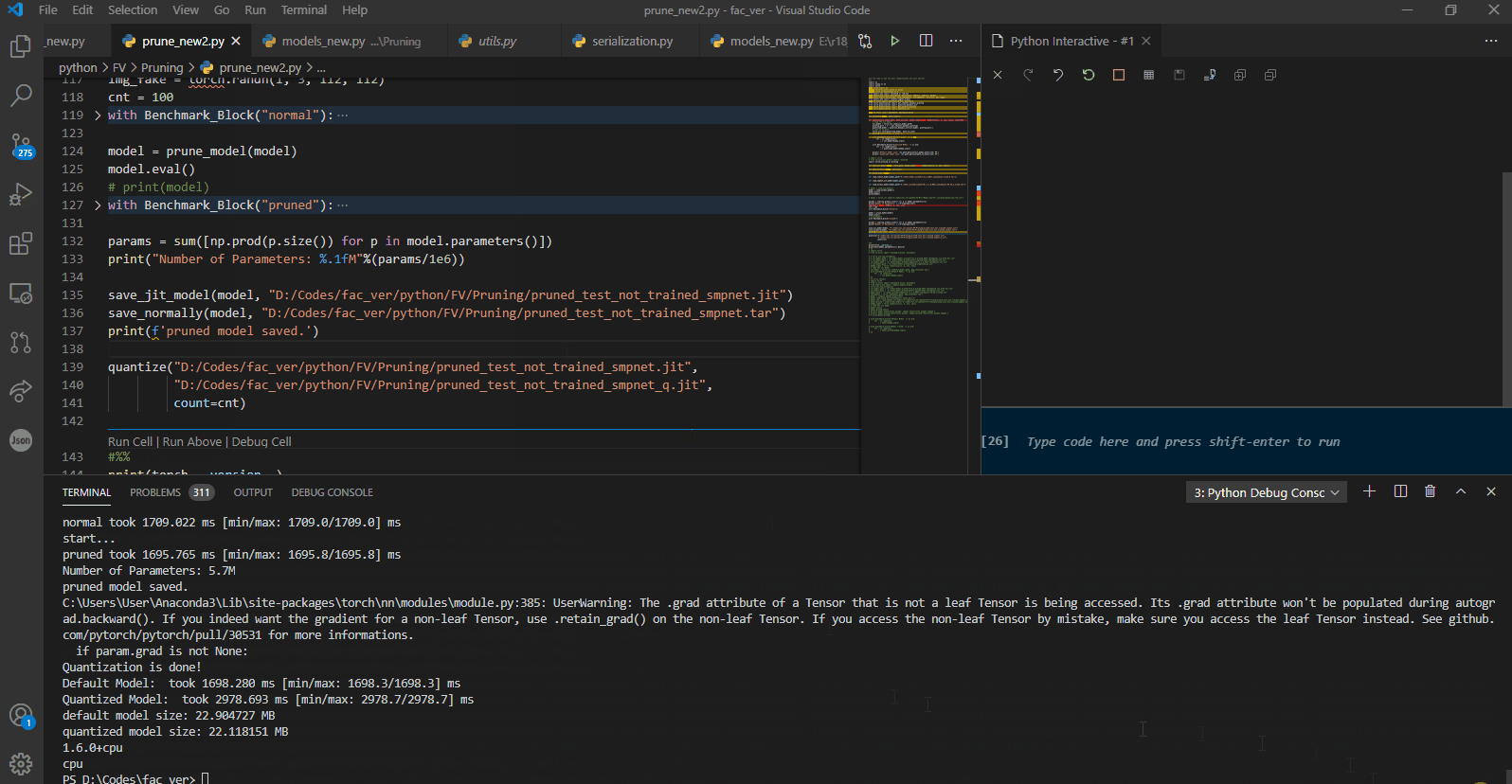
Here is the live run of the process, showing the pruned model is indeed faster, but the quantized model for some reason is extremely slow :

I also tested this with another model, and the outcome is the same. the quantized model takes much more to finish:
Note :
As you can see, we do not finetune the pruned model here. we are just testing whether the pruning by nature results in faster inference in our case or not, and as t he results show, it indeed does.
Finetuning an already pruned model for some reason, results in a sever slow down at inferece as you can see.