I am learning pytorch and coded a minimal classifier to play with:
import torch
import numpy as np
import matplotlib.pyplot as plt
numclasses, count = 8, 200
x = torch.randn(count, 4)
y = torch.randint(0, numclasses, size=[count])
dataset = torch.utils.data.TensorDataset(x, y)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=20, shuffle = True)
model = torch.nn.Sequential(
torch.nn.Linear(4, 20),
torch.nn.ReLU(),
torch.nn.Linear(20, numclasses),
torch.nn.Softmax(dim=1))
lossf = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
losses = []
for epoch in range(30):
for batch in dataloader:
x, y = batch
out = model(x)
loss = lossf(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append( loss.item() )
plt.plot(losses)
This is what I get with full dataset (batch_size = 200):
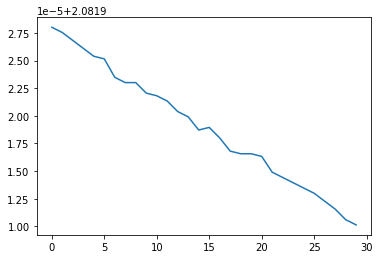
And this is with mini-batch (batch_size = 20):
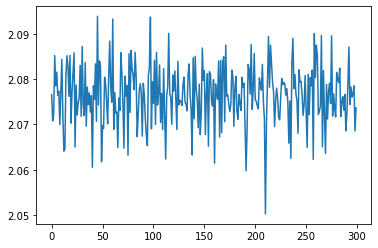
Any idea why this happens?
Could this ever happen in real problems with real data?