Asya
September 15, 2021, 2:09pm
1
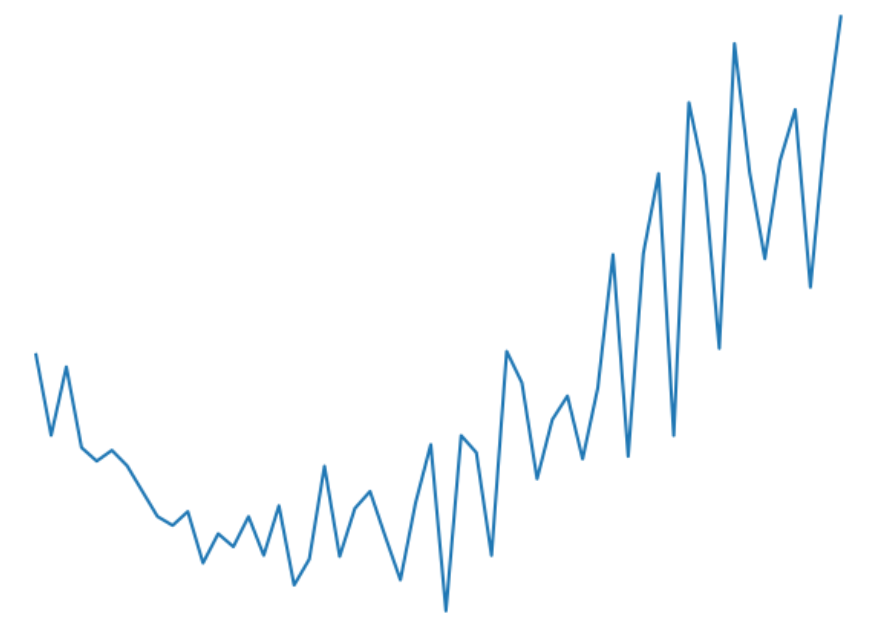
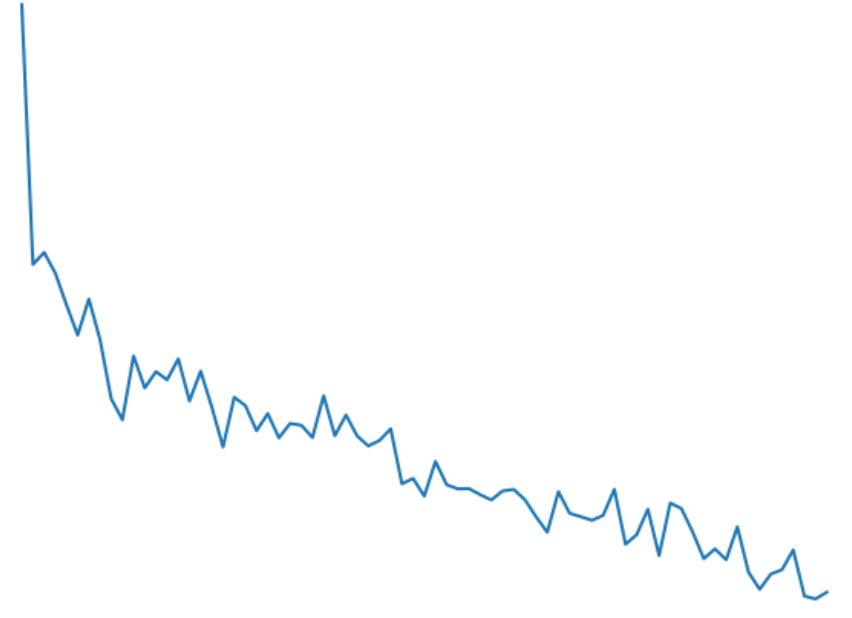
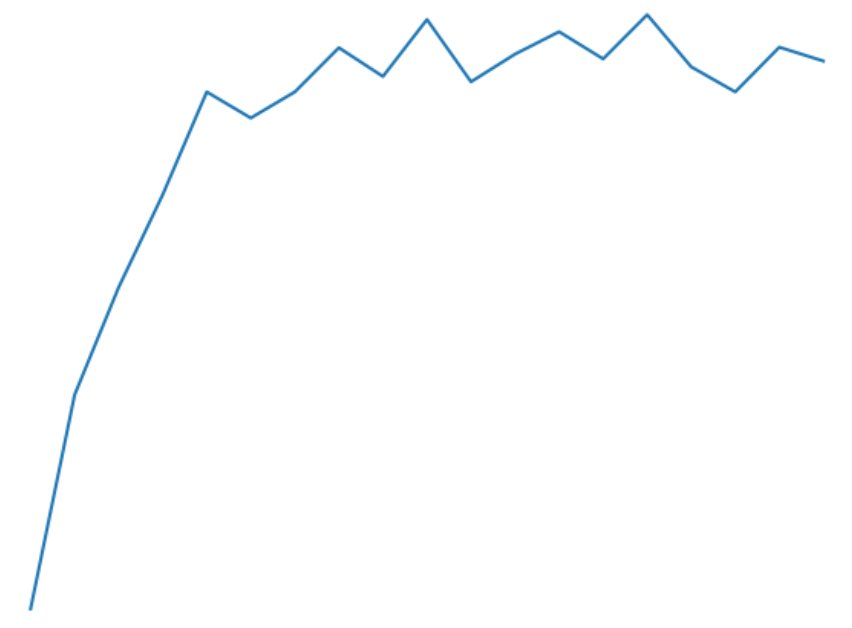
my validation loss increases while training loss decreases, and accuracy increases for both validation and training
I’m trying to find a reason why could that be and how to fix it. Is it overfitting or can it be something else?
validation loss:
train loss:
validation accuracy:
train accuracy:
lxm-001
September 15, 2021, 2:20pm
2
it seems like the overfitting problem,and you need to check the function of validation func.
Asya
September 15, 2021, 2:23pm
3
this is my function, is there anything I can fix here?
def train_model(model, criterion, optimizer, num_epochs):
best_acc = 0.0
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs))
print('-' * 10)
loss_train = 0
loss_val = 0
acc_train = 0
acc_val = 0
min_valid_loss = np.inf
# model.train(True)
for batch, (inputs, labels) in enumerate(train_data):
inputs, labels = inputs.cuda(), labels.cuda()
# Clear the gradients
optimizer.zero_grad()
# Forward Pass
outputs = model(inputs)
# Find the Loss
loss = criterion(outputs, labels)
# Calculate gradients
loss.backward()
# Update Weights
optimizer.step()
# Calculate Loss
loss_train += float(loss)
_, preds = torch.max(outputs.data, 1)
acc_train += int(torch.sum(preds == labels.data)) / len(preds)
avg_loss = loss_train / len(train_data)
avg_acc = acc_train / len(train_data)
for batch, (inputs, labels) in enumerate(val_data):
inputs, labels = inputs.cuda(), labels.cuda()
# Forward Pass
outputs = model(inputs)
# Find the Loss
loss = criterion(outputs, labels)
# Calculate Loss
loss_val += loss.item()
_, preds = torch.max(outputs.data, 1)
acc_val += int(torch.sum(preds == labels.data)) / len(preds)
del inputs, labels, outputs, preds
torch.cuda.empty_cache()
avg_loss_val = loss_val / len(val_data)
avg_acc_val = acc_val / len(val_data)
print()
print("Epoch {} result: ".format(epoch))
print("Avg loss (train): {:.4f}".format(avg_loss))
print("Avg acc (train): {:.4f}".format(avg_acc))
print("Avg loss (val): {:.4f}".format(avg_loss_val))
print("Avg acc (val): {:.4f}".format(avg_acc_val))
print('-' * 10)
print()
if avg_acc_val > best_acc:
best_acc = avg_acc_val
best_model_wts = copy.deepcopy(model.state_dict())
print("Best acc: ", best_acc)
model.load_state_dict(best_model_wts)
return model
lxm-001
September 15, 2021, 2:32pm
4
it has some problems ,first , it seems you not change to eval model ,try to use model.eval(), and you not stop the backward ,try to use " with torch.no_grad()"
lxm-001
September 15, 2021, 2:37pm
5
and you even not clear the loss in the last time in the eval model,maybe it is the issue of your problem
Asya
September 15, 2021, 2:42pm
6
where should I change for modal.eval() mode? for training or for validation?
and I did cleaning like that before
del inputs, labels, outputs, preds
torch.cuda.empty_cache()
after training part, but it didn’t help
Asya
September 15, 2021, 5:09pm
7
so I tried different ways with switching eval mode and added with torch.no_grad() but it still didn’t improve anything
Gorgen
May 2, 2022, 11:04am
8
hello. sorry to disturb you. I meet the same issue. Could you please give me some advice how to solve it? Thanks, Best wishes