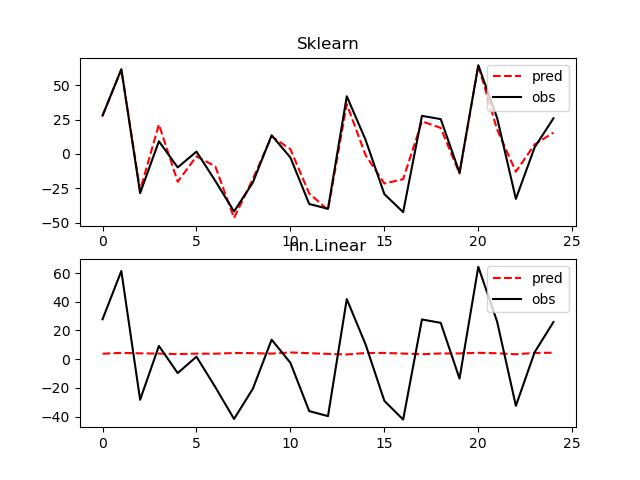
I tried to solved the very simple equation y = ax1 + bx2 + cx3 + d using nn.Linear. The pearsonr is only 0.331. But the sklearn’s LinearRegression gave me good results and its pearsonr is 0.943. Can someone tell me why? My code is as follows:
(My torch.version is ‘1.11.0’)
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.stats import pearsonr
import torch
# generate data
x, y, coef = datasets.make_regression(n_samples=100, n_features=3, n_targets=1, n_informative=2, bias=3.5, noise=10,
coef=True, random_state=42)
train_x, val_x, train_y, val_y = train_test_split(x, y)
# using sklearn
# y = ax1 + bx2 + cx3 + d
LR = LinearRegression()
LR.fit(train_x, train_y)
pred_sklearn = LR.predict(val_x)
print(pearsonr(val_y, pred_sklearn)[0])
# using nn.Linear
class LinearRegression(torch.nn.Module):
def __init__(self, input_dim, outp_dim):
super(LinearRegression, self).__init__()
self.linear = torch.nn.Linear(input_dim, outp_dim)
def forward(self, x):
out = self.linear(x)
return out
inp_dim = 3
opt_dim = 1
LR = 0.01
EPOCHS = 100
model = LinearRegression(inp_dim, opt_dim)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
train_x = torch.from_numpy(train_x).to(torch.float32)
train_y = torch.from_numpy(train_y).to(torch.float32)
val_x = torch.from_numpy(val_x).to(torch.float32)
val_y = torch.from_numpy(val_y).to(torch.float32)
for epoch in range(EPOCHS):
optimizer.zero_grad()
pred = model(train_x)
loss = loss_fn(pred, train_y)
print(loss)
loss.backward()
optimizer.step()
corr = pearsonr(train_y.numpy(), pred.detach().numpy())[0][0]
print("Epoch {}, loss {}, Corr {}.".format(epoch, loss.item(), corr))
with torch.no_grad():
pred_val = model(val_x)
corr = pearsonr(val_y.numpy(), pred_val.numpy())[0][0]
print("Validation Corr {}".format(corr))
# plot
fig, axs = plt.subplots(2, 1)
axs[0].plot(pred_sklearn, "r--", label="pred")
axs[0].plot(val_y, "k-", label="obs")
axs[0].set_title("Sklearn")
axs[0].legend()
axs[1].plot(pred_val, "r--", label="pred")
axs[1].plot(val_y, "k-", label="obs")
axs[1].set_title("nn.Linear")
axs[1].legend()
plt.savefig("linear_regression.jpg")
plt.show()
Your LinearRegression model is purely a linear output so it won’t be able to reproduce a polynomial function. Try including an additional layer with a non-linear function and see if that improves your loss.
For example,
# using nn.Linear
class LinearRegression(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, outp_dim):
super(LinearRegression, self).__init__()
self.linear1 = torch.nn.Linear(input_dim, hidden_dim)
self.af = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(hidden_dim, outp_dim)
def forward(self, x):
out = self.linear1(x)
out = self.af(out)
out = self.linear2(out)
return out
The problem is that your model returns pred of shape [nBatch, 1],
while MSELoss expects the shape to be [nBatch] (assuming that train_y has shape [nBatch]).
You should use squeeze() to remove pred’s trailing singleton dimension:
loss = loss_fn (pred.squeeze(), train_y)
Did you post the same code that you ran? It generates (among others) the
following error:
UserWarning: Using a target size (torch.Size([75])) that is different to the input size (torch.Size([75, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
Here’s the full output when I run your code:
0.9434504563774768
<path_to_conda_install>\lib\site-packages\torch\nn\modules\loss.py:520: UserWarning: Using a target size (torch.Size([75])) that is different to the input size (torch.Size([75, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
tensor(935.8654, grad_fn=<MseLossBackward0>)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 53, in <module>
File "<path_to_conda_install>\lib\site-packages\scipy\stats\stats.py", line 3519, in pearsonr
xmean = x.mean(dtype=dtype)
File "<path_to_conda_install>\lib\site-packages\numpy\core\_methods.py", line 75, in _mean
ret = umr_sum(arr, axis, dtype, out, keepdims)
TypeError: No loop matching the specified signature and casting
was found for ufunc add
Here is the code I ran, copied from your original post:
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.stats import pearsonr
import torch
# generate data
x, y, coef = datasets.make_regression(n_samples=100, n_features=3, n_targets=1, n_informative=2, bias=3.5, noise=10, coef=True, random_state=42)
train_x, val_x, train_y, val_y = train_test_split(x, y)
# using sklearn
# y = ax1 + bx2 + cx3 + d
LR = LinearRegression()
LR.fit(train_x, train_y)
pred_sklearn = LR.predict(val_x)
print(pearsonr(val_y, pred_sklearn)[0])
# using nn.Linear
class LinearRegression(torch.nn.Module):
def __init__(self, input_dim, outp_dim):
super(LinearRegression, self).__init__()
self.linear = torch.nn.Linear(input_dim, outp_dim)
def forward(self, x):
out = self.linear(x)
return out
inp_dim = 3
opt_dim = 1
LR = 0.01
EPOCHS = 100
model = LinearRegression(inp_dim, opt_dim)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
train_x = torch.from_numpy(train_x).to(torch.float32)
train_y = torch.from_numpy(train_y).to(torch.float32)
val_x = torch.from_numpy(val_x).to(torch.float32)
val_y = torch.from_numpy(val_y).to(torch.float32)
for epoch in range(EPOCHS):
optimizer.zero_grad()
pred = model(train_x)
loss = loss_fn(pred, train_y)
print(loss)
loss.backward()
optimizer.step()
corr = pearsonr(train_y.numpy(), pred.detach().numpy())[0][0]
print("Epoch {}, loss {}, Corr {}.".format(epoch, loss.item(), corr))
with torch.no_grad():
pred_val = model(val_x)
corr = pearsonr(val_y.numpy(), pred_val.numpy())[0][0]
print("Validation Corr {}".format(corr))
# plot
fig, axs = plt.subplots(2, 1)
axs[0].plot(pred_sklearn, "r--", label="pred")
axs[0].plot(val_y, "k-", label="obs")
axs[0].set_title("Sklearn")
axs[0].legend()
axs[1].plot(pred_val, "r--", label="pred")
axs[1].plot(val_y, "k-", label="obs")
axs[1].set_title("nn.Linear")
axs[1].legend()
plt.savefig("linear_regression.jpg")
plt.show()
Further detail: When I correct the main error by using squeeze(), your
pytorch training works:
Here is the (slightly) modified code:
from sklearn import datasets
# import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from scipy.stats import pearsonr
import torch
print (torch.__version__)
import sklearn
print (sklearn.__version__)
_ = torch.manual_seed (2022)
# generate data
x, y, coef = datasets.make_regression(n_samples=100, n_features=3, n_targets=1, n_informative=2, bias=3.5, noise=10, coef=True, random_state=42)
train_x, val_x, train_y, val_y = train_test_split(x, y, random_state = 42)
# using sklearn
# y = ax1 + bx2 + cx3 + d
LR = LinearRegression()
LR.fit(train_x, train_y)
pred_sklearn = LR.predict(val_x)
print(pearsonr(val_y, pred_sklearn)[0])
# using nn.Linear
class LinearRegression(torch.nn.Module):
def __init__(self, input_dim, outp_dim):
super(LinearRegression, self).__init__()
self.linear = torch.nn.Linear(input_dim, outp_dim)
def forward(self, x):
out = self.linear(x)
return out
inp_dim = 3
opt_dim = 1
LR = 0.01
EPOCHS = 100
model = LinearRegression(inp_dim, opt_dim)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
train_x = torch.from_numpy(train_x).to(torch.float32)
train_y = torch.from_numpy(train_y).to(torch.float32)
val_x = torch.from_numpy(val_x).to(torch.float32)
val_y = torch.from_numpy(val_y).to(torch.float32)
print ('train_x.shape:', train_x.shape)
print ('train_y.shape:', train_y.shape)
for epoch in range(EPOCHS):
optimizer.zero_grad()
pred = model(train_x)
pred = pred.squeeze() # make pred the same shape as train_y
loss = loss_fn(pred, train_y)
print(loss)
loss.backward()
optimizer.step()
# corr = pearsonr(train_y.numpy(), pred.detach().numpy())[0][0]
corr = pearsonr(train_y.numpy(), pred.detach().numpy())[0] # fix indexing error
print("Epoch {}, loss {}, Corr {}.".format(epoch, loss.item(), corr))
with torch.no_grad():
pred_val = model(val_x)
pred_val = pred_val.squeeze() # make pred_val the same shape as val_y
# corr = pearsonr(val_y.numpy(), pred_val.numpy())[0][0]
corr = pearsonr(val_y.numpy(), pred_val.numpy())[0] # fix indexing error
print("Validation Corr {}".format(corr))
# don't generate plots ...
And here is its output:
1.10.2
0.23.2
0.9644607867821674
train_x.shape: torch.Size([75, 3])
train_y.shape: torch.Size([75])
tensor(927.5605, grad_fn=<MseLossBackward0>)
Epoch 0, loss 927.560546875, Corr 0.8665461367914611.
tensor(899.4070, grad_fn=<MseLossBackward0>)
Epoch 1, loss 899.406982421875, Corr 0.8963448364399582.
tensor(872.2882, grad_fn=<MseLossBackward0>)
Epoch 2, loss 872.2882080078125, Corr 0.9045393770552396.
tensor(846.1624, grad_fn=<MseLossBackward0>)
Epoch 3, loss 846.1624145507812, Corr 0.9084728376837197.
tensor(820.9895, grad_fn=<MseLossBackward0>)
Epoch 4, loss 820.989501953125, Corr 0.9109301157061639.
tensor(796.7314, grad_fn=<MseLossBackward0>)
Epoch 5, loss 796.7313842773438, Corr 0.9127151167963403.
tensor(773.3514, grad_fn=<MseLossBackward0>)
Epoch 6, loss 773.3513793945312, Corr 0.9141388557186239.
tensor(750.8146, grad_fn=<MseLossBackward0>)
Epoch 7, loss 750.8146362304688, Corr 0.9153452353725057.
tensor(729.0876, grad_fn=<MseLossBackward0>)
Epoch 8, loss 729.087646484375, Corr 0.9164095315550076.
tensor(708.1384, grad_fn=<MseLossBackward0>)
Epoch 9, loss 708.1383666992188, Corr 0.9173747610570682.
tensor(687.9362, grad_fn=<MseLossBackward0>)
Epoch 10, loss 687.9361572265625, Corr 0.9182672382770966.
tensor(668.4520, grad_fn=<MseLossBackward0>)
Epoch 11, loss 668.4519653320312, Corr 0.9191039211035062.
tensor(649.6574, grad_fn=<MseLossBackward0>)
Epoch 12, loss 649.6574096679688, Corr 0.919896248525179.
tensor(631.5258, grad_fn=<MseLossBackward0>)
Epoch 13, loss 631.5257568359375, Corr 0.9206522240575098.
tensor(614.0313, grad_fn=<MseLossBackward0>)
Epoch 14, loss 614.0313110351562, Corr 0.9213775889557101.
tensor(597.1494, grad_fn=<MseLossBackward0>)
Epoch 15, loss 597.1493530273438, Corr 0.9220766038610609.
tensor(580.8564, grad_fn=<MseLossBackward0>)
Epoch 16, loss 580.8563842773438, Corr 0.9227524968114652.
tensor(565.1298, grad_fn=<MseLossBackward0>)
Epoch 17, loss 565.1297607421875, Corr 0.9234077559452655.
tensor(549.9479, grad_fn=<MseLossBackward0>)
Epoch 18, loss 549.9478759765625, Corr 0.9240443355509959.
tensor(535.2899, grad_fn=<MseLossBackward0>)
Epoch 19, loss 535.2899169921875, Corr 0.924663804706848.
tensor(521.1360, grad_fn=<MseLossBackward0>)
Epoch 20, loss 521.1360473632812, Corr 0.9252674435362963.
tensor(507.4673, grad_fn=<MseLossBackward0>)
Epoch 21, loss 507.46728515625, Corr 0.9258563069125514.
tensor(494.2652, grad_fn=<MseLossBackward0>)
Epoch 22, loss 494.26519775390625, Corr 0.9264312576627101.
tensor(481.5125, grad_fn=<MseLossBackward0>)
Epoch 23, loss 481.512451171875, Corr 0.9269930423825647.
tensor(469.1921, grad_fn=<MseLossBackward0>)
Epoch 24, loss 469.192138671875, Corr 0.927542303971793.
tensor(457.2883, grad_fn=<MseLossBackward0>)
Epoch 25, loss 457.28826904296875, Corr 0.9280795932204553.
tensor(445.7852, grad_fn=<MseLossBackward0>)
Epoch 26, loss 445.7852478027344, Corr 0.9286053891451324.
tensor(434.6685, grad_fn=<MseLossBackward0>)
Epoch 27, loss 434.66845703125, Corr 0.929120119540763.
tensor(423.9235, grad_fn=<MseLossBackward0>)
Epoch 28, loss 423.92352294921875, Corr 0.92962415430261.
tensor(413.5369, grad_fn=<MseLossBackward0>)
Epoch 29, loss 413.536865234375, Corr 0.9301178376075808.
tensor(403.4954, grad_fn=<MseLossBackward0>)
Epoch 30, loss 403.495361328125, Corr 0.9306014850132069.
tensor(393.7865, grad_fn=<MseLossBackward0>)
Epoch 31, loss 393.7864990234375, Corr 0.931075370063931.
tensor(384.3982, grad_fn=<MseLossBackward0>)
Epoch 32, loss 384.3981628417969, Corr 0.9315397506251142.
tensor(375.3189, grad_fn=<MseLossBackward0>)
Epoch 33, loss 375.31890869140625, Corr 0.9319948687240436.
tensor(366.5374, grad_fn=<MseLossBackward0>)
Epoch 34, loss 366.5373840332031, Corr 0.9324409529382404.
tensor(358.0431, grad_fn=<MseLossBackward0>)
Epoch 35, loss 358.0430908203125, Corr 0.932878223886074.
tensor(349.8257, grad_fn=<MseLossBackward0>)
Epoch 36, loss 349.8257141113281, Corr 0.9333068596448737.
tensor(341.8754, grad_fn=<MseLossBackward0>)
Epoch 37, loss 341.8753967285156, Corr 0.9337270523110779.
tensor(334.1826, grad_fn=<MseLossBackward0>)
Epoch 38, loss 334.1826171875, Corr 0.9341389826965887.
tensor(326.7384, grad_fn=<MseLossBackward0>)
Epoch 39, loss 326.7383728027344, Corr 0.9345428165678584.
tensor(319.5338, grad_fn=<MseLossBackward0>)
Epoch 40, loss 319.5338439941406, Corr 0.934938725446739.
tensor(312.5606, grad_fn=<MseLossBackward0>)
Epoch 41, loss 312.5606384277344, Corr 0.9353268578596723.
tensor(305.8106, grad_fn=<MseLossBackward0>)
Epoch 42, loss 305.8106384277344, Corr 0.9357073704567556.
tensor(299.2762, grad_fn=<MseLossBackward0>)
Epoch 43, loss 299.2761535644531, Corr 0.936080404182596.
tensor(292.9496, grad_fn=<MseLossBackward0>)
Epoch 44, loss 292.9496154785156, Corr 0.9364460996929919.
tensor(286.8239, grad_fn=<MseLossBackward0>)
Epoch 45, loss 286.8238830566406, Corr 0.9368045941817736.
tensor(280.8920, grad_fn=<MseLossBackward0>)
Epoch 46, loss 280.89202880859375, Corr 0.9371560209168424.
tensor(275.1474, grad_fn=<MseLossBackward0>)
Epoch 47, loss 275.14739990234375, Corr 0.9375005010662267.
tensor(269.5835, grad_fn=<MseLossBackward0>)
Epoch 48, loss 269.5835266113281, Corr 0.9378381736287246.
tensor(264.1943, grad_fn=<MseLossBackward0>)
Epoch 49, loss 264.1943054199219, Corr 0.9381691561075034.
tensor(258.9738, grad_fn=<MseLossBackward0>)
Epoch 50, loss 258.9738464355469, Corr 0.9384935715459056.
tensor(253.9163, grad_fn=<MseLossBackward0>)
Epoch 51, loss 253.91632080078125, Corr 0.9388115315493336.
tensor(249.0163, grad_fn=<MseLossBackward0>)
Epoch 52, loss 249.01632690429688, Corr 0.9391231559124964.
tensor(244.2685, grad_fn=<MseLossBackward0>)
Epoch 53, loss 244.26849365234375, Corr 0.9394285663433485.
tensor(239.6677, grad_fn=<MseLossBackward0>)
Epoch 54, loss 239.66773986816406, Corr 0.9397278563604841.
tensor(235.2092, grad_fn=<MseLossBackward0>)
Epoch 55, loss 235.20916748046875, Corr 0.9400211478814218.
tensor(230.8880, grad_fn=<MseLossBackward0>)
Epoch 56, loss 230.8880157470703, Corr 0.9403085460779028.
tensor(226.6998, grad_fn=<MseLossBackward0>)
Epoch 57, loss 226.69976806640625, Corr 0.9405901512016184.
tensor(222.6400, grad_fn=<MseLossBackward0>)
Epoch 58, loss 222.6399688720703, Corr 0.9408660661323613.
tensor(218.7044, grad_fn=<MseLossBackward0>)
Epoch 59, loss 218.70440673828125, Corr 0.9411364029876472.
tensor(214.8890, grad_fn=<MseLossBackward0>)
Epoch 60, loss 214.8890380859375, Corr 0.9414012515759894.
tensor(211.1898, grad_fn=<MseLossBackward0>)
Epoch 61, loss 211.18984985351562, Corr 0.9416607096595627.
tensor(207.6031, grad_fn=<MseLossBackward0>)
Epoch 62, loss 207.60305786132812, Corr 0.9419148789599142.
tensor(204.1250, grad_fn=<MseLossBackward0>)
Epoch 63, loss 204.1250457763672, Corr 0.9421638529299052.
tensor(200.7522, grad_fn=<MseLossBackward0>)
Epoch 64, loss 200.7522430419922, Corr 0.9424077269336291.
tensor(197.4812, grad_fn=<MseLossBackward0>)
Epoch 65, loss 197.48123168945312, Corr 0.9426465925791531.
tensor(194.3088, grad_fn=<MseLossBackward0>)
Epoch 66, loss 194.30880737304688, Corr 0.9428805381893856.
tensor(191.2317, grad_fn=<MseLossBackward0>)
Epoch 67, loss 191.23171997070312, Corr 0.9431096571688113.
tensor(188.2469, grad_fn=<MseLossBackward0>)
Epoch 68, loss 188.2469024658203, Corr 0.9433340413180376.
tensor(185.3514, grad_fn=<MseLossBackward0>)
Epoch 69, loss 185.35142517089844, Corr 0.9435537717996456.
tensor(182.5425, grad_fn=<MseLossBackward0>)
Epoch 70, loss 182.54248046875, Corr 0.9437689304929312.
tensor(179.8172, grad_fn=<MseLossBackward0>)
Epoch 71, loss 179.81724548339844, Corr 0.9439796079582918.
tensor(177.1731, grad_fn=<MseLossBackward0>)
Epoch 72, loss 177.173095703125, Corr 0.9441858874998488.
tensor(174.6075, grad_fn=<MseLossBackward0>)
Epoch 73, loss 174.60745239257812, Corr 0.9443878521890566.
tensor(172.1179, grad_fn=<MseLossBackward0>)
Epoch 74, loss 172.11785888671875, Corr 0.9445855731388954.
tensor(169.7019, grad_fn=<MseLossBackward0>)
Epoch 75, loss 169.701904296875, Corr 0.9447791367105692.
tensor(167.3573, grad_fn=<MseLossBackward0>)
Epoch 76, loss 167.35728454589844, Corr 0.9449686215611789.
tensor(165.0818, grad_fn=<MseLossBackward0>)
Epoch 77, loss 165.08177185058594, Corr 0.9451541015864174.
tensor(162.8732, grad_fn=<MseLossBackward0>)
Epoch 78, loss 162.8732147216797, Corr 0.9453356544541982.
tensor(160.7296, grad_fn=<MseLossBackward0>)
Epoch 79, loss 160.72955322265625, Corr 0.9455133516073128.
tensor(158.6487, grad_fn=<MseLossBackward0>)
Epoch 80, loss 158.64869689941406, Corr 0.9456872696999288.
tensor(156.6287, grad_fn=<MseLossBackward0>)
Epoch 81, loss 156.6287384033203, Corr 0.9458574834322825.
tensor(154.6678, grad_fn=<MseLossBackward0>)
Epoch 82, loss 154.66781616210938, Corr 0.9460240571994823.
tensor(152.7641, grad_fn=<MseLossBackward0>)
Epoch 83, loss 152.76406860351562, Corr 0.9461870691771925.
tensor(150.9158, grad_fn=<MseLossBackward0>)
Epoch 84, loss 150.915771484375, Corr 0.946346587383633.
tensor(149.1212, grad_fn=<MseLossBackward0>)
Epoch 85, loss 149.1211700439453, Corr 0.9465026683671753.
tensor(147.3787, grad_fn=<MseLossBackward0>)
Epoch 86, loss 147.37869262695312, Corr 0.9466553905844401.
tensor(145.6868, grad_fn=<MseLossBackward0>)
Epoch 87, loss 145.68675231933594, Corr 0.9468048151286164.
tensor(144.0437, grad_fn=<MseLossBackward0>)
Epoch 88, loss 144.04373168945312, Corr 0.9469510050411061.
tensor(142.4482, grad_fn=<MseLossBackward0>)
Epoch 89, loss 142.44818115234375, Corr 0.9470940321129467.
tensor(140.8987, grad_fn=<MseLossBackward0>)
Epoch 90, loss 140.89871215820312, Corr 0.947233938455497.
tensor(139.3939, grad_fn=<MseLossBackward0>)
Epoch 91, loss 139.39385986328125, Corr 0.9473708112771287.
tensor(137.9323, grad_fn=<MseLossBackward0>)
Epoch 92, loss 137.93231201171875, Corr 0.9475046989787301.
tensor(136.5127, grad_fn=<MseLossBackward0>)
Epoch 93, loss 136.5127410888672, Corr 0.9476356603672296.
tensor(135.1339, grad_fn=<MseLossBackward0>)
Epoch 94, loss 135.13389587402344, Corr 0.9477637519492872.
tensor(133.7945, grad_fn=<MseLossBackward0>)
Epoch 95, loss 133.79452514648438, Corr 0.9478890330360974.
tensor(132.4935, grad_fn=<MseLossBackward0>)
Epoch 96, loss 132.4935302734375, Corr 0.9480115612849499.
tensor(131.2297, grad_fn=<MseLossBackward0>)
Epoch 97, loss 131.2296905517578, Corr 0.9481313961921827.
tensor(130.0019, grad_fn=<MseLossBackward0>)
Epoch 98, loss 130.00192260742188, Corr 0.9482485850842012.
tensor(128.8091, grad_fn=<MseLossBackward0>)
Epoch 99, loss 128.80914306640625, Corr 0.9483631842089812.
Validation Corr 0.9536379006945159
As you can see, the training proceeds sensibly, with the loss falling
and the correlation (corr) increasing, and the final validation correlation
is quite good, with Validation Corr 0.9536379006945159.
As an aside, you don’t need to wrap Linear in your own custom LinearRegression model – just using Linear directly suffices
(and is completely equivalent):
UserWarning: Using a target size (torch.Size([75])) that is different to the input size (torch.Size([75, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
It worked after I added squeeze() and modified one line.
pred = pred.squeeze()
corr = pearsonr(train_y.numpy(), pred.detach().numpy())[0]
Thanks!
By the way, I checked why this warning was causing problems, and I found that the different input sizes give different results:
import torch
from torch.nn import MSELoss
x1 = torch.asarray([1.,2,3])
x2 = x1.reshape(3,1)
y = torch.asarray([3.,7,2])
loss1 = MSELoss()(x1, y)
loss2 = MSELoss()(x2, y)
print("x shape: {}. y shape {}. loss {}".format(x1.shape, y.shape, loss1))
print("x shape: {}. y shape {}. loss {}".format(x2.shape, y.shape, loss2))
output:
UserWarning: Using a target size (torch.Size([3])) that is different to the input size (torch.Size([3, 1])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
return F.mse_loss(input, target, reduction=self.reduction)
x shape: torch.Size([3]). y shape torch.Size([3]). loss 10.0
x shape: torch.Size([3, 1]). y shape torch.Size([3]). loss 9.333333015441895