Hi, I’m running an allreduce with torch.distributed on a cluster of 2 AWS P4d instances (2*8 A100 GPUs).
I’m launching the 16 processes with MPI, and the allreduce with that function:
def run(rank, local_rank):
""" Simple allreduce. """
tensor = torch.rand(int(1e6)*args.tensor_size_mm, dtype=torch.float32).to(cuda)
t1 = time.time()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
dist.barrier()
t2 = time.time()
return tensor.element_size()*tensor.numel()/1e6, t2-t1
results = [] # average over N allreduces to remove jitter
for i in range(args.n_attempts):
size, duration = run(WORLD_RANK, LOCAL_RANK)
results.append(duration)
print("Run {} - allreduce of {}MB tensor done in {}s".format(
i, size, duration))
I run 5 allreduces one after the other to remove the impact of network jitter. Suprisingly, the measured allreduce duration is vastly different on every GPU! with differences as big as 5x ratio. Below a measurement I did with a 8GB tensor
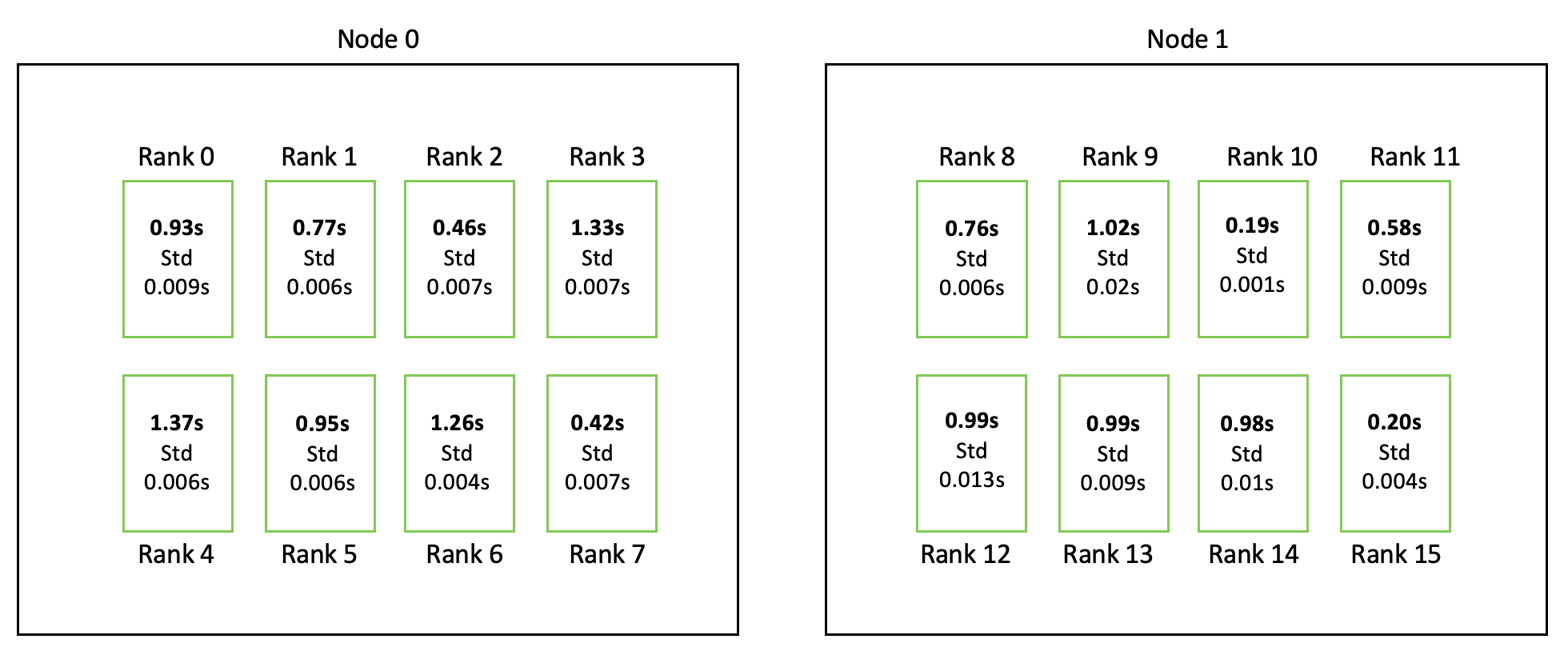
Why does each GPU measures a different allreduce time? What is the proper way to measure the duration of an allreduce operation, if all processes report something different