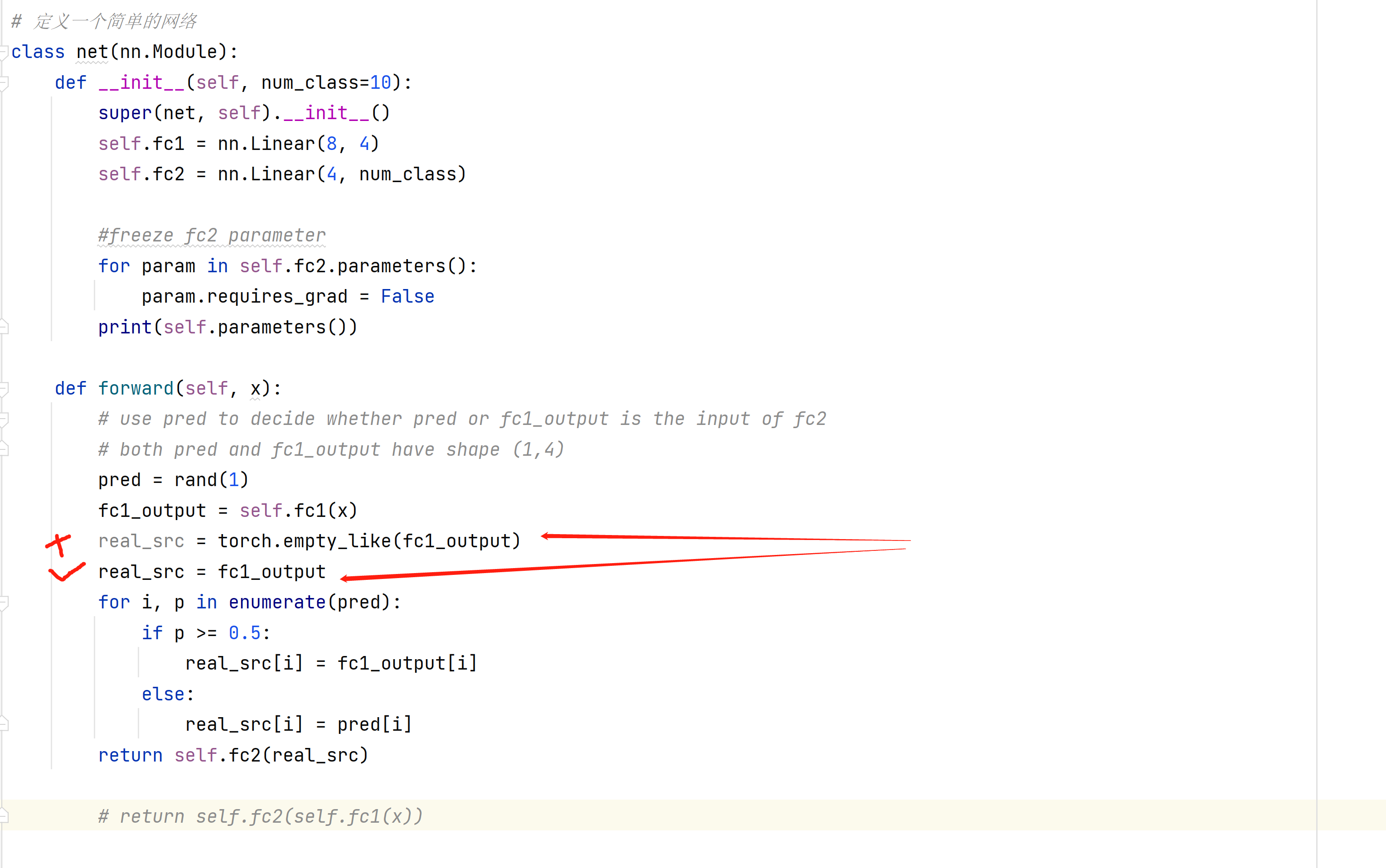
If use empty_like , this error occur:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
class net(nn.Module):
def __init__(self, num_class=10):
super(net, self).__init__()
self.fc1 = nn.Linear(8, 4)
self.fc2 = nn.Linear(4, num_class)
#freeze fc2 parameter
for param in self.fc2.parameters():
param.requires_grad = False
print(self.parameters())
def forward(self, x):
# use pred to decide whether pred or fc1_output is the input of fc2
# both pred and fc1_output have shape (1,4)
pred = rand(1)
fc1_output = self.fc1(x)
# if use this , will error
real_src = torch.empty_like(fc1_output)
# correct
real_src = fc1_output
for i, p in enumerate(pred):
if p >= 0.5:
real_src[i] = fc1_output[i]
else:
real_src[i] = pred[i]
return self.fc2(real_src)
# return self.fc2(self.fc1(x))