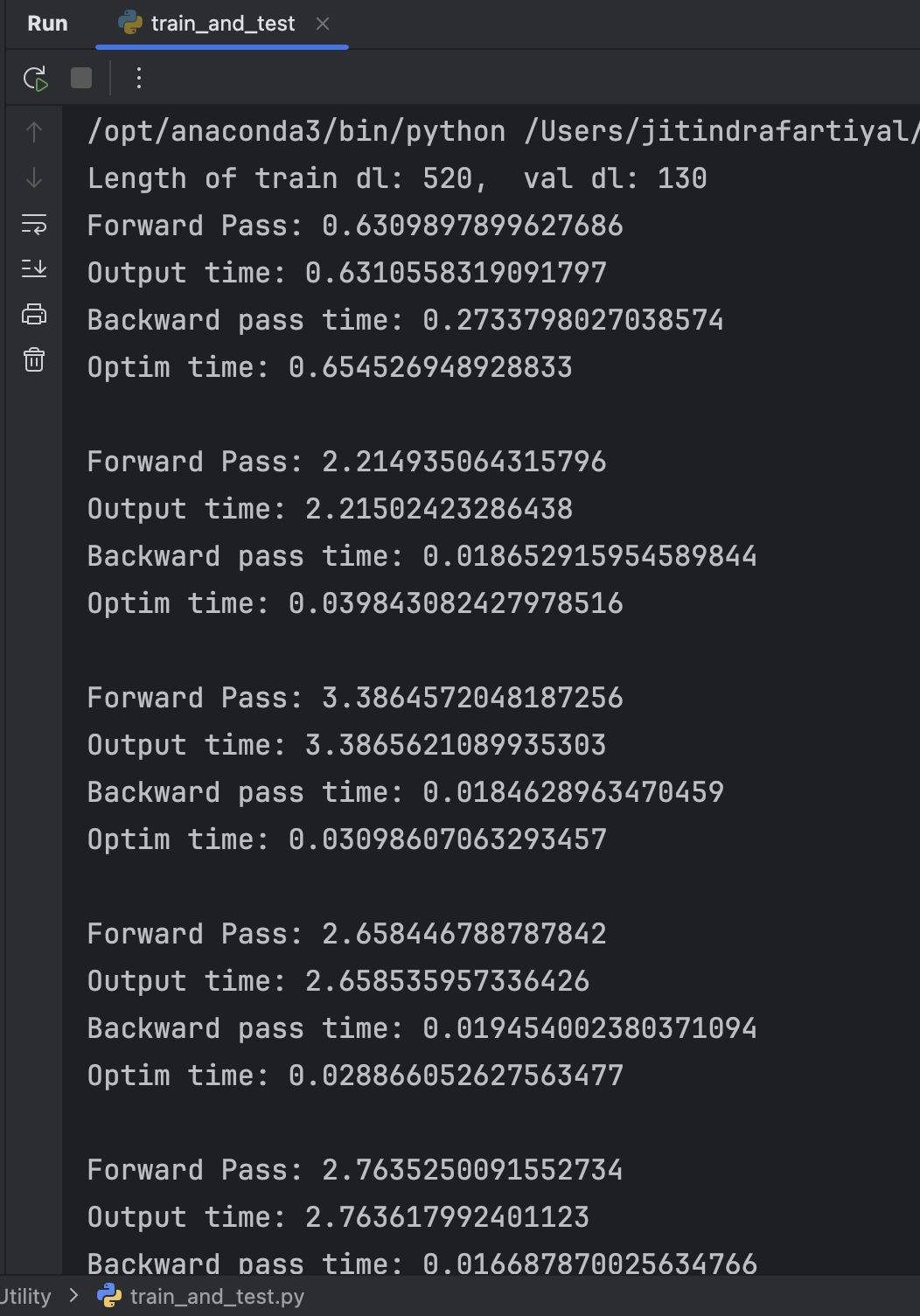
Why the first forward pass is faster than the rest of the forward pass.
Device: Mac (mps)
Batch size: 8
num_workers: 0
pin_memory: True
torch.backends.cudnn.benchmark = True
Model Architecture: 2D UNET model
Input Image Size: 256
Code:
def train_one_epoch(device, model, dl, optim, loss):
start_time = time()
total_loss = 0.
model.train()
for i, batch in enumerate(dl):
optim.zero_grad(set_to_none=True)
input, target = batch[0].to(device, non_blocking=True), batch[1].to(device, non_blocking=True)
output_start_time = time()
output = model(input)
print(f'Output time: {time()-output_start_time}')
torch.mps.empty_cache()
batch_loss = loss(output, target)
total_loss += batch_loss.item()
backward_start_time = time()
batch_loss.backward()
print(f'Backward pass time: {time() - backward_start_time}')
optim_start_time = time()
optim.step()
print(f'Optim time: {time() - optim_start_time} \n')
if i >=5:
break
return total_loss/len(dl), time()-start_time