I must set ‘retain_graph=True’ as the input parameter of ‘backward()’ in order to make my program run without error message, or I will get this messsge:
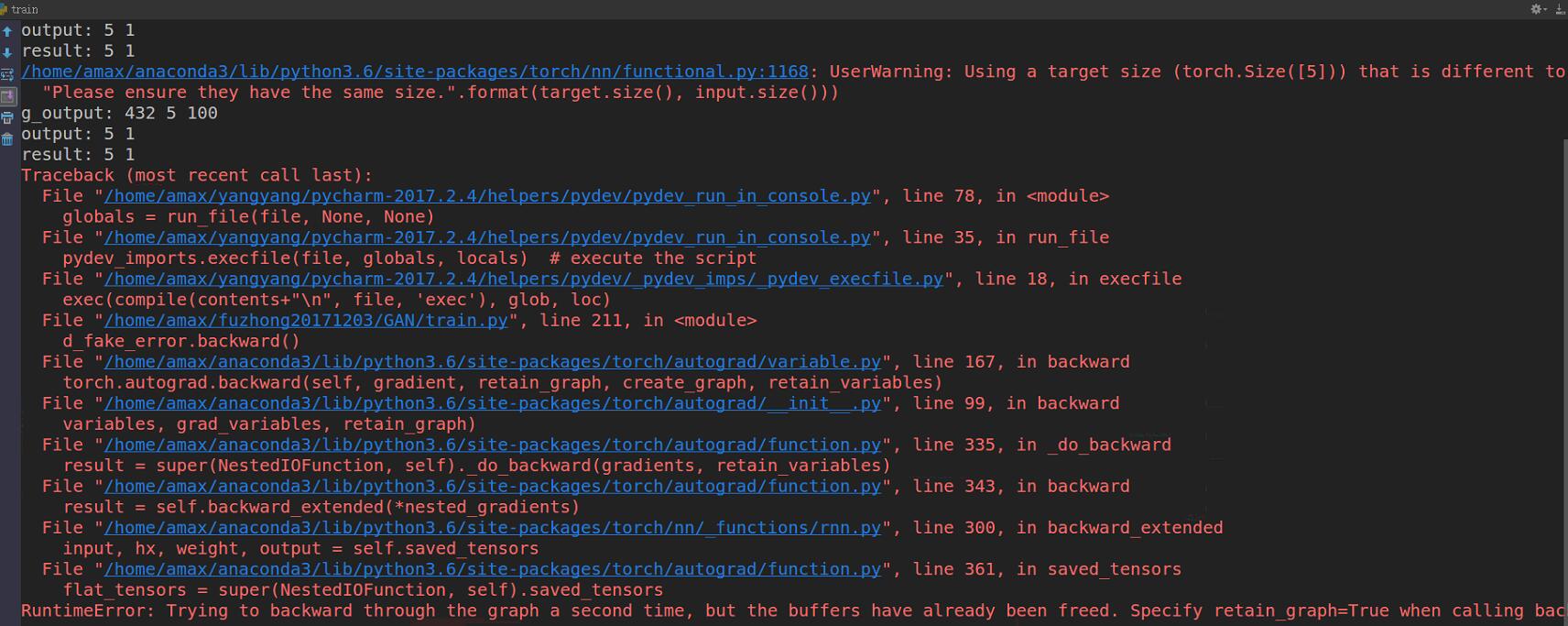
If I add ‘retain_graph=True’ to ‘backward()’, my GPU memory will soon be depleted. So I can’t add it.
I don’t know why this happened? Based on official documentation, ‘retain_graph’ is optional. I think there must be sth wrong in my code. However, I’m fresh in python and pytorch so I couldn’t find out the error by myself. Can someone figure out the problem in my code? My code as below:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import scipy.io as s
import h5py
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
# Read data and convert to Tensor
file_path = "../database/frameLength100/notOverlap/trainset/trainset.mat"
mat_data = s.loadmat(file_path)
# mat_data = h5py.File(file_path)
np_data = []
np_data = mat_data['trainset'][:, :, :]
# data = torch.FloatTensor(matdata['a'])
# temp = torch.from_numpy(np_data).float() #Tensor
# temp = torch.FloatTensor(np_data)
# tensor_data = temp.permute(2,1,0)
class CustomDataset(Dataset):
def __init__(self, tensor_data):
temp = torch.from_numpy(tensor_data).float()
self.tensor_data = temp # .permute(2,1,0)
def __getitem__(self, index):
data = self.tensor_data[:, index, :]
label = 1;
return data, label
def __len__(self):
return self.tensor_data.size(1)
custom_dataset = CustomDataset(tensor_data=np_data)
train_loader = DataLoader(dataset=custom_dataset, batch_size=5, shuffle=True)
# Define variable
# Model params
g_input_size = 100 # Random noise dimension coming into generator, per output vector
g_hidden_size = 200 # Generator complexity
g_output_size = 100 # size of generated output vector
g_timestep_size = 432 # duration of one ECG record
g_layer_num = 2 # num of generator layer
g_batch_size = 5 # batch size of generator
d_input_size = 100 # size of discriminative input vector
d_hidden_size = 200 # Discriminator complexity
d_output_size = 1 # Single dimension for 'real' vs. 'fake'
d_layer_num = 1 # num of discriminator layer
d_batch_size = 5 # batch size of discriminator
# minibatch_size = d_input_size
d_learning_rate = 0.0001
g_learning_rate = 0.0001
optim_betas = (0.9, 0.999)
num_epochs = 100
print_interval = 100
d_steps = 1 # 'k' steps in the original GAN paper. Can put the discriminator on higher training freq than generator
g_steps = 1
# noise for generator input
def get_generator_input_sampler(m, n, k):
# return lambda m, n, k: torch.randn(m, n, k) # Uniform-dist data into generator, input m,n, output torch.rand(m, n)
temp = torch.randn(m, n, k)
noisy = torch.zeros(m, n, k)
for i in range(n):
temp1 = temp[:, i, :]
temp2 = (temp1 - torch.min(temp1))/((torch.max(temp1) - torch.min(temp1)))
noisy[:, i, :] = temp2*2 - 1
return noisy
# ##### MODELS: Generator model and discriminator model
class Generator(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers, batch_size):
super(Generator, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.batch_size = batch_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.proj = nn.Linear(hidden_size, output_size)
self.hidden = self.init_hidden()
# self.gen = nn.Sequential(
# nn.LSTMCell(input_size, hidden_size),
# nn.LSTMCell(hidden_size, hidden_size),
# nn.Linear(hidden_size, output_size)
# )
def init_hidden(self):
h0 = torch.randn(self.num_layers, self.batch_size, self.hidden_size)
c0 = torch.randn(self.num_layers, self.batch_size, self.hidden_size)
h0 = h0.cuda()
c0 = c0.cuda()
return (Variable(h0), Variable(c0))
def forward(self, x):
x1 = F.normalize(x)
lstm_out, self.hidden = self.lstm(x1, self.hidden)
output = self.proj(lstm_out)
print('g_output: %d %d %d' % output.size())
return output
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers, batch_size):
super(Discriminator, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.batch_size = batch_size
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.proj = nn.Linear(hidden_size, output_size)
self.pool = nn.AvgPool1d(432)
self.hidden = self.init_hidden()
def init_hidden(self):
h0 = torch.randn(self.num_layers, self.batch_size, self.hidden_size)
c0 = torch.randn(self.num_layers, self.batch_size, self.hidden_size)
h0 = h0.cuda()
c0 = c0.cuda()
return (Variable(h0), Variable(c0))
def forward(self, x):
# x1 = F.normalize(x)
lstm_out, self.hidden = self.lstm(x, self.hidden)
output = self.proj(lstm_out[-1])
print('output: %d %d' % output.size())
# for j in range(output.size(1)):
# output1 = self.pool(output)
# print('output1: %d %d %d' % output1.size())
result = F.sigmoid(output)
print('result: %d %d' % result.size())
return result
# gi_sampler = get_generator_input_sampler()
G = Generator(input_size=g_input_size, hidden_size=g_hidden_size, output_size=g_output_size, num_layers=g_layer_num, batch_size=g_batch_size)
D = Discriminator(input_size=d_input_size, hidden_size=d_hidden_size, output_size=d_output_size, num_layers=d_layer_num, batch_size=d_batch_size)
criterion = nn.BCELoss()
for name, param in D.named_parameters():
if 'bias' in name:
nn.init.constant(param, 0.0)
elif 'weight' in name:
nn.init.xavier_normal(param)
for name, param in G.named_parameters():
if 'bias' in name:
nn.init.constant(param, 0.0)
elif 'weight' in name:
nn.init.xavier_normal(param)
if torch.cuda.is_available():
D.cuda()
G.cuda()
criterion.cuda()
d_optimizer = optim.Adam(D.parameters(), lr=d_learning_rate, betas=optim_betas)
g_optimizer = optim.Adam(G.parameters(), lr=g_learning_rate, betas=optim_betas)
for epoch in range(num_epochs):
for i, (data, label) in enumerate(train_loader, 0):
# 1. Train D on real+fake
D.zero_grad()
data = data.permute(2,0,1)
# 1A: Train D on real
if torch.cuda.is_available():
data = data.cuda()
d_real_data = Variable(data)
print('data: %d %d %d' % d_real_data.size())
d_real_decision = D(d_real_data)
# print('d_real_decision: %d %d' % d_real_decision.size())
d_real_error = criterion(d_real_decision, Variable(torch.ones(data.size(1)).cuda()))
d_real_error.backward(retain_graph=True)
D_x = d_real_decision.data.mean()
# 1B: Train D on fake
noise = get_generator_input_sampler(g_timestep_size, g_batch_size, g_input_size)
if torch.cuda.is_available():
noise = noise.cuda()
d_gen_input = Variable(noise)
d_fake_data = G(d_gen_input).detach()
d_fake_decision = D(d_fake_data)
d_fake_error = criterion(d_fake_decision, Variable(torch.zeros(data.size(1)).cuda()))
d_fake_error.backward(retain_graph=True)
d_loss = d_real_error + d_fake_error
D_G_z1 = d_fake_decision.data.mean()
d_optimizer.step()
# 2. Train G on D's response (but DO NOT train D on these labels)
G.zero_grad()
noise1 = get_generator_input_sampler(g_timestep_size, g_batch_size, g_input_size)
if torch.cuda.is_available():
noise1 = noise1.cuda()
gen_input = Variable(noise1)
g_fake_data = G(gen_input)
dg_fake_decision = D(g_fake_data)
g_error = criterion(dg_fake_decision, Variable(torch.ones(data.size(1)).cuda()))
g_error.backward(retain_graph=True)
D_G_z2 = dg_fake_decision.data.mean()
g_optimizer.step() # Only optimizes G's parameters