I used the dataloader for the test_data. Below is the dataset:
class Test_Data1(Dataset):
# Constructor
def __init__(self):
test_data = numpy.load('x_test.npy')
test_labels = numpy.load('y_test.npy')
test_data = test_data
self.x = test_data
self.y = test_labels
self.len = self.x.shape[0]
# Getter
def __getitem__(self, index):
return self.x[index], self.y[index]
# Get length
def __len__(self):
return self.len
This is my test code:
test_dataset1 = Test_Data1()
test_loader1 = DataLoader(dataset=test_dataset1, batch_size=360, shuffle=False)
correct = 0
total = 0
for data in test_loader1:
inputs, labels = data
print(labels)
labels = labels.type(torch.LongTensor)
inputs = inputs.view(-1, 1024).double()
outputs =model1(inputs.float())
_, predicted = torch.max(outputs.data, 1)
print(predicted)
total += labels.size(0)
correct += (predicted == labels).sum()
print(100 * correct /float(total))
By comparison of the output, I found that the order was changed.
My order
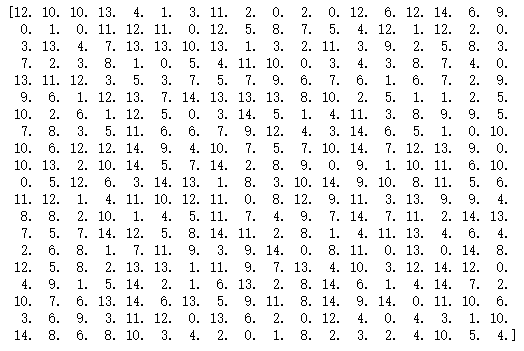
The output order from dataloader:
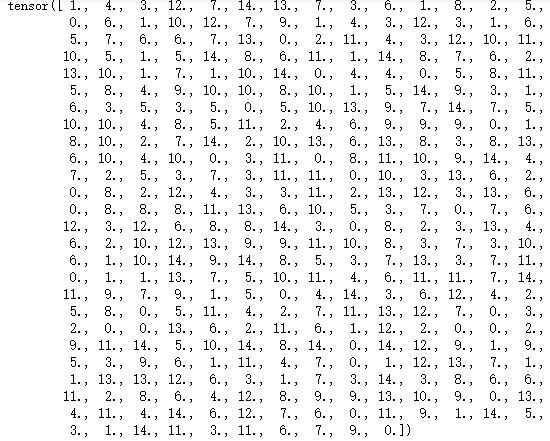
Looking forward to your reply.
Best regards,
William