Hi everyone,
I’m new to deep learning and started by implementing an autoencoder for time-series data, which seemed simple enough, or so I thought. However, the model performance gets worse (even on training data) as I make the model deeper, which doesn’t make any sense to me. Here’s my first autoencoder (model 1), implemented in PyTorch:
# model 1
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# encoder
self.enc1 = nn.Linear(in_features=512, out_features=256)
self.enc2 = nn.Linear(in_features=256, out_features=128)
self.enc3 = nn.Linear(in_features=128, out_features=64)
# decoder
self.dec1 = nn.Linear(in_features=64, out_features=128)
self.dec2 = nn.Linear(in_features=128, out_features=256)
self.dec3 = nn.Linear(in_features=256, out_features=512)
def forward(self, x):
# encoder
x = F.relu(self.enc1(x))
x = F.relu(self.enc2(x))
x = F.relu(self.enc3(x))
# decoder
x = F.relu(self.dec1(x))
x = F.relu(self.dec2(x))
x = self.dec3(x) # no RELU on the last one
return x
Pretty straightforward… Just a vanilla autoencoder using fully-connected layers. I am able to train this model with a training set of over 200k examples using MSELoss() and Adam optimizer (LR = 1e-3). But the loss (even for the training set) doesn’t go down as low as I want it to go, so I made the model just one layer deeper at each stage (model 2) to see if it would train better:
# model 2
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# encoder
self.enc0 = nn.Linear(in_features=512, out_features=512)
self.enc1 = nn.Linear(in_features=512, out_features=256)
self.enc2 = nn.Linear(in_features=256, out_features=256)
self.enc3 = nn.Linear(in_features=256, out_features=128)
self.enc4 = nn.Linear(in_features=128, out_features=128)
self.enc5 = nn.Linear(in_features=128, out_features=64)
self.enc6 = nn.Linear(in_features=64, out_features=64)
# decoder
self.dec0 = nn.Linear(in_features=64, out_features=64)
self.dec1 = nn.Linear(in_features=64, out_features=128)
self.dec2 = nn.Linear(in_features=128, out_features=128)
self.dec3 = nn.Linear(in_features=128, out_features=256)
self.dec4 = nn.Linear(in_features=256, out_features=256)
self.dec5 = nn.Linear(in_features=256, out_features=512)
self.dec6 = nn.Linear(in_features=512, out_features=512)
def forward(self, x):
# encoder
x = F.relu(self.enc0(x))
x = F.relu(self.enc1(x))
x = F.relu(self.enc2(x))
x = F.relu(self.enc3(x))
x = F.relu(self.enc4(x))
x = F.relu(self.enc5(x))
x = F.relu(self.enc6(x))
# decoder
x = F.relu(self.dec0(x))
x = F.relu(self.dec1(X))
x = F.relu(self.dec2(x))
x = F.relu(self.dec3(x))
x = F.relu(self.dec4(x))
x = F.relu(self.dec5(x))
x = self.dec6(x) # no RELU on the last one
return x
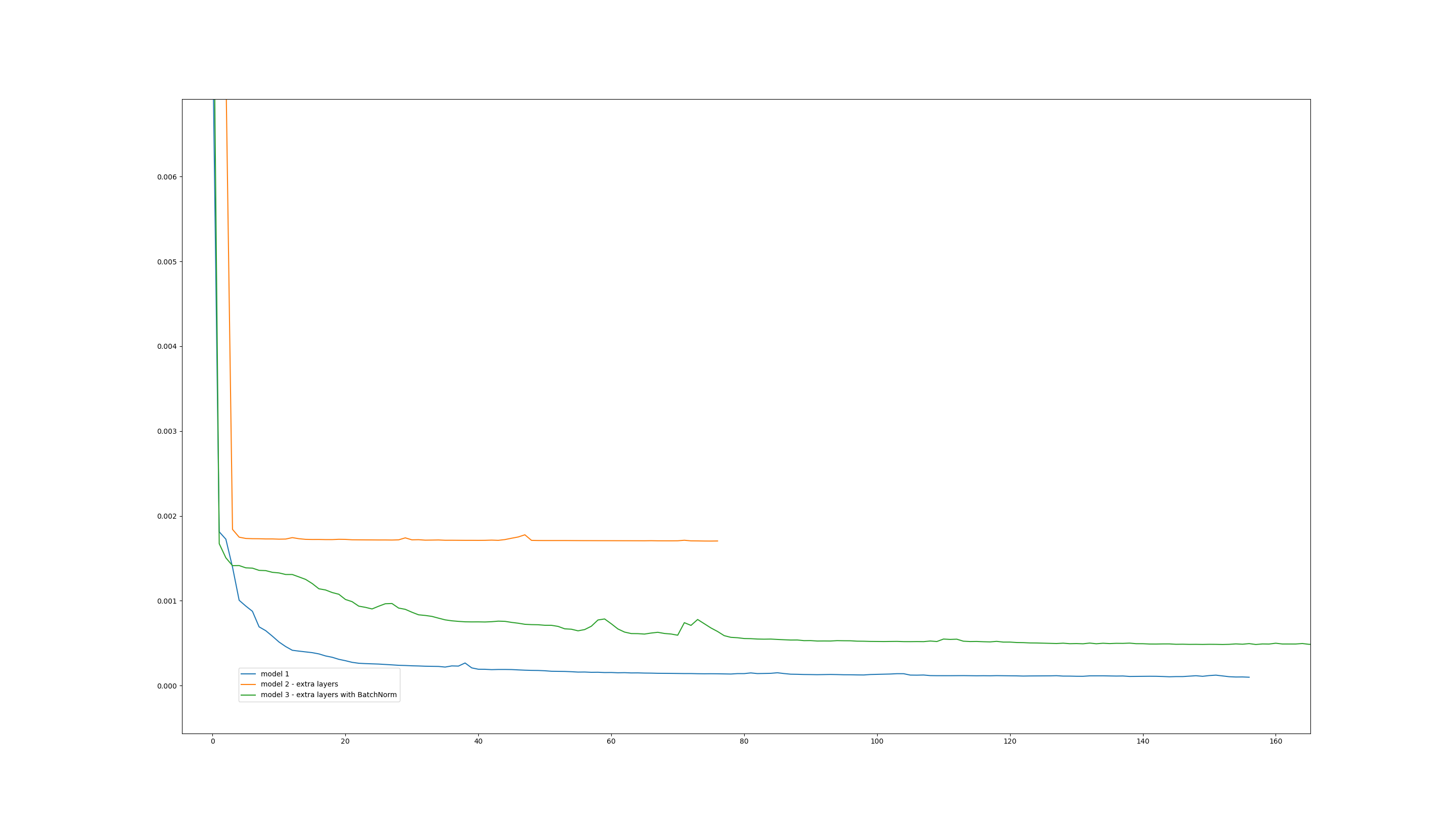
As you can see, all I am doing is adding an extra fully-connected layer to each stage of the auto-encoder. This is a very simple change that I thought would improve performance. After all, the whole point of deeper networks is that they can learn useful features that encode the signal better. So I was very surprised when I trained this and it ended up working much worse:

Note that this convergence plot shows the loss on the TRAINING SET, so we’re not even talking test set here so overfitting is not the issue. I tried increasing the learning rate and also letting it run longer, but it doesn’t seem to get out of this local minimum. When I repeat the experiment, it keeps converging to that minimum, almost as if this is the best it can do. This is very surprising because I thought in the very least model 2 would be NO WORSE than model 1, since the additional layers could simply learn an identity function, so the performance of model 2 should be better than (or at least equal to) that of model 1.
So I’m almost embarrassed to ask: what am I doing wrong here? I’ve been reading about the problems with deep networks and am not sure if those problems apply here. For example, vanishing gradients can be a problem when the networks get too deep, but the fact that I am using ReLUs and that my network is not THAT deep somehow ameliorates that issue, I would think.
Any suggestions? Sorry about the total n00b question, but I feel that if I can’t even get a simple autoencoder working I’m in trouble. Thanks in advance for your help!
 I will experiment a bit with residual connections, etc.
I will experiment a bit with residual connections, etc.