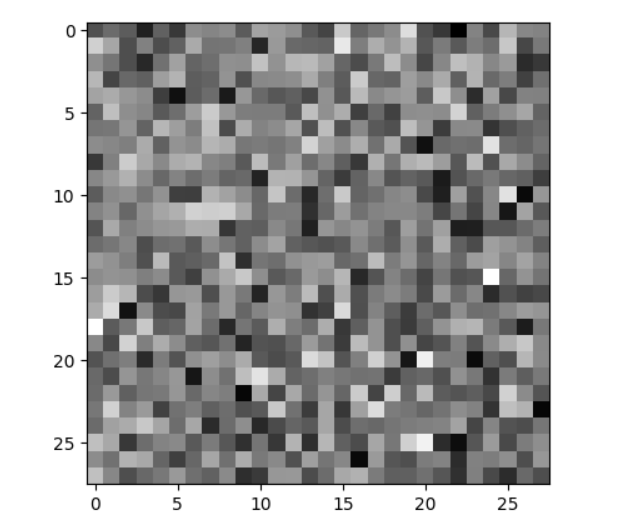
I am using a simple autoencoder to learn images from the FashionMnist dataset. I have preprocessed the dataset by grayscaling and normalizing it. I did not make the network too deep, to prevent it from creating a direct mapping.
Here’s my PyTorch code -
import torch
import torchvision as tv
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch import nn
import os
from torchviz import make_dot
transforms = tv.transforms.Compose([tv.transforms.Grayscale(num_output_channels=1)])
trainset = tv.datasets.FashionMNIST(root='./data', train=True,
download=True, transform=transforms)
PATH = './ae.pth'
data = trainset.data.float()
data = data/255
# print(trainset.data.shape)
plt.imshow(trainset.data[0], cmap = 'gray')
plt.show()
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.encode = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 30),
nn.ReLU()
)
self.decode = nn.Sequential(
nn.Linear(30, 512),
nn.ReLU(),
nn.Linear(512, 28*28),
nn.Sigmoid()
)
def forward(self, x):
x = self.flatten(x)
encoded = self.encode(x)
decoded = self.decode(encoded)
return decoded
if(os.path.exists(PATH)):
print("Loading data on cpu")
device = torch.device('cpu')
model = NeuralNetwork()
model.load_state_dict(torch.load(PATH, map_location=device))
else:
device = "cuda" if torch.cuda.is_available() else "cpu"
data = data.to(device)
print(f"Using device = {device}")
model = NeuralNetwork().to(device)
# print(model)
lossFn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 1e-3)
for epoch in range(1000):
print("Epoch = ", epoch)
optimizer.zero_grad()
outputs = model(data)
loss = lossFn(outputs, data.reshape(-1, 784))
loss.backward()
optimizer.step()
torch.save(model.state_dict(), PATH)
data = data.to("cpu")
model = model.to("cpu")
pred = model(data)
pred = pred.reshape(-1, 28, 28)
# print(pred.shape)
plt.imshow(pred.detach().numpy()[0], cmap = 'gray')
plt.show()
For testing, I am inputting the following image -
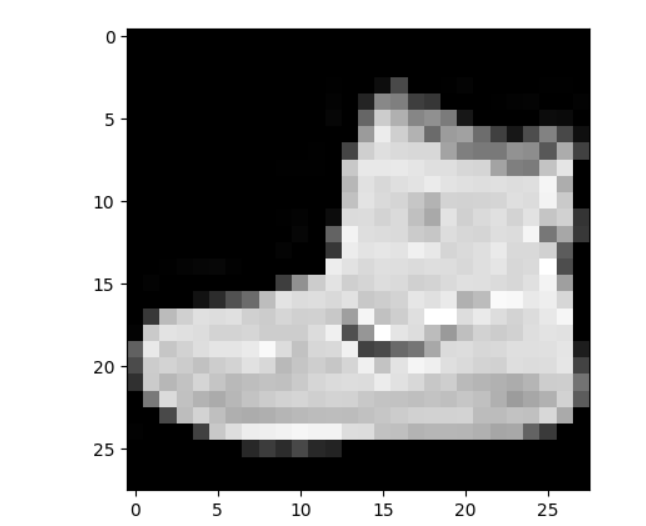
The following image gets outputted -