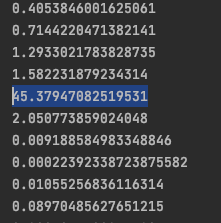
I am training a DQN (Deep Q Network) on a CartPole problem from OpenAI’s gym, but the total score from an episode decreases, instead of increasing. I don’t know if it is helpful but I noticed that the AI prefers one action over another and refuses to do anything else (unless it is forced by the epsilon greedy strategy), at least for some time. I tried my best, but I just can’t figure out what is going on.
Here is my code:
(qlearning.py)
import torch as t
import torch.nn as nn
import torch.nn.functional as f
import random as r
class QNet:
def predict(self, x: t.Tensor) -> t.Tensor:
pass
@staticmethod
def copy_weights(origin: [], target: []):
for origin_layer, target_layer in zip(origin, target):
target_layer.weight = nn.Parameter(origin_layer.weight.clone())
class Memory:
def __init__(self, state: t.Tensor, next_state: t.Tensor, action: int, reward: float):
self.state = state
self.next_state = next_state
self.action = action
self.reward = reward
class ReplayMemory:
def __init__(self, capacity: int):
self.capacity = capacity
self.memories = []
def add_memory(self, memory: Memory):
self.memories.append(memory)
if len(self.memories) > self.capacity:
self.memories.pop(0)
def get_batch(self, size: int):
if len(self.memories) < size:
raise Exception("There are not enough memories to make a batch.")
start_index = r.randint(0, len(self.memories) - size)
end_index = start_index + size
return self.memories[start_index:end_index]
class QLearning:
def __init__(self, net: QNet, target_net: QNet, optimizer, gamma: float):
self.net = net
self.target_net = target_net
self.optimizer = optimizer
self.gamma = gamma
def train(self, batch: [Memory]):
batched_pred = []
batched_opt_pred = []
for sample in batch:
pred = self.net.predict(sample.state)
opt_pred = pred.clone()
opt_pred[sample.action] = sample.reward
if sample.next_state is not None:
opt_pred[sample.action] += t.max(self.target_net.predict(sample.next_state)) * self.gamma
batched_pred.append(pred)
batched_opt_pred.append(opt_pred)
loss = f.mse_loss(t.stack(batched_pred), t.stack(batched_opt_pred))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
(main.py)
import gym
from qlearning import *
env = gym.make("CartPole-v1")
state = t.tensor(env.reset(), dtype=t.float)
class Agent(nn.Module, QNet):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(4, 32)
self.l2 = nn.Linear(32, 16)
self.l3 = nn.Linear(16, 8)
self.l4 = nn.Linear(8, 4)
self.l5 = nn.Linear(4, 2)
def predict(self, x):
y = f.relu(self.l1(x))
y = f.relu(self.l2(y))
y = f.relu(self.l3(y))
y = f.relu(self.l4(y))
return self.l5(y)
agent = Agent()
target_agent = Agent()
q = QLearning(agent, target_agent, optim.Adam(agent.parameters(), lr=0.001), 0.9)
replay_memory = ReplayMemory(100000)
epsilon = 1
epsilon_dec = 1 / 1000
total_reward = 0
for i in range(1000):
env.render()
action = 0
if r.random() > epsilon:
action = t.argmax(agent.predict(state)).item()
else:
action = env.action_space.sample()
epsilon -= epsilon_dec
next_state, reward, done, info = env.step(action)
next_state = t.tensor(next_state, dtype=t.float)
if done:
reward = -1
replay_memory.add_memory(Memory(state, None, action, reward))
else:
replay_memory.add_memory(Memory(state, next_state, action, reward))
total_reward += reward
if done:
state = t.tensor(env.reset(), dtype=t.float)
# print(int(total_reward))
total_reward = 0
if len(replay_memory.memories) >= 10:
q.train(replay_memory.get_batch(10))
if i % 10:
QNet.copy_weights([agent.l1, agent.l2, agent.l3, agent.l4, agent.l5],
[target_agent.l1, target_agent.l2, target_agent.l3, target_agent.l4, target_agent.l5])
state = next_state
env.close()