Hello everyone,
I’m working on implementing pipeline parallelism in my model using Pippy’s ScheduleGPipe, but I’ve encountered an issue where the loss remains consistently at 2.3 throughout training. I have checked several aspects of my implementation, including data loading, model structure, and optimization settings, but I cannot seem to find what’s causing this behavior.
I followed the example provided by Pippy for setting up the pipeline parallelism. I am aware that Pippy has been deprecated, but since I need to use it for now, I’m trying to understand why my setup isn’t working as expected. Specifically, I noticed that when using from torch.distributed.pipelining import PipelineStage, the example code does not include an input_args parameter, which causes errors during execution in my environment (PyTorch 2.51 + CPU).
Here are some details about my setup:
I have divided my model into multiple chunks, each handled by a different rank.
Each rank has its own optimizer that should only update the parameters of the chunk it owns.
The loss calculation and backpropagation are performed only on the last rank (rank == world_size - 1).
I have verified that the batch sizes for both the output and target match.
I have also included checks for gradients to ensure they are not None or contain NaN/Inf.
Despite these precautions, the loss does not decrease from its initial value of approximately 2.3. Could there be something wrong with how I’ve set up the pipeline parallelism or parameter updates?
# Copyright (c) Meta Platforms, Inc. and affiliates
# Minimal effort to run this code:
# $ torchrun --nproc-per-node 3 example_manual_stage.py
import os
import torch
import torch.distributed as dist
from pippy import ScheduleGPipe, ManualPipelineStage
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, DistributedSampler
in_dim = 784
layer_dims = [512, 1024, 256]
out_dim = 10
# Single layer definition
class MyNetworkBlock(torch.nn.Module):
def __init__(self, in_dim, out_dim):
super().__init__()
self.lin = torch.nn.Linear(in_dim, out_dim)
def forward(self, x):
x = self.lin(x)
# x = torch.relu(x)
return x
class ModelChunk0(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer0 = MyNetworkBlock(in_dim, layer_dims[0])
def forward(self, x):
return self.layer0(x)
class ModelChunk1(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer1 = MyNetworkBlock(layer_dims[0], layer_dims[1])
def forward(self, x):
return self.layer1(x)
class ModelChunk2(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer2 = MyNetworkBlock(layer_dims[1], layer_dims[2])
self.output_proj = torch.nn.Linear(layer_dims[2], out_dim)
def forward(self, x):
x = self.layer2(x)
return self.output_proj(x)
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
dist.init_process_group(rank=rank, world_size=world_size)
if torch.cuda.is_available():
device = torch.device(f"cuda:{rank % torch.cuda.device_count()}")
else:
device = torch.device("cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
chunks = 1
batch_size = 32
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_sampler = DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=rank
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)
example_input_stage_0 = torch.randn(batch_size, in_dim, device=device)
example_input_stage_1 = torch.randn(batch_size, layer_dims[0], device=device)
example_input_stage_2 = torch.randn(batch_size, layer_dims[1], device=device)
rank_model_and_input = {
0: (ModelChunk0(), example_input_stage_0),
1: (ModelChunk1(), example_input_stage_1),
2: (ModelChunk2(), example_input_stage_2),
}
if rank in rank_model_and_input:
model, example_input = rank_model_and_input[rank]
stage = ManualPipelineStage(
model,
rank,
world_size,
device,
chunks,
example_input,
)
print(f"Rank {rank} initialized")
else:
raise RuntimeError("Invalid rank")
# Attach to a schedule
schedule = ScheduleGPipe(stage, chunks)
def train(rank, world_size, schedule, device, train_loader):
if rank == world_size - 1:
optimizer = torch.optim.Adam(rank_model_and_input[rank][0].parameters(), lr=0.001)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1):
train_loader.sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
data = data.view(data.size(0), -1)
if rank == 0:
output = schedule.step(data)
else:
output = schedule.step()
if rank == world_size - 1:
loss = criterion(output, target)
print(f'Rank {rank}, Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 10 == 0 and rank == world_size - 1:
print(f'Rank {rank}, Epoch {epoch}, Batch {batch_idx}')
if rank in rank_model_and_input:
train(rank, world_size, schedule, device, train_loader)
print(f"Rank {rank} finished")
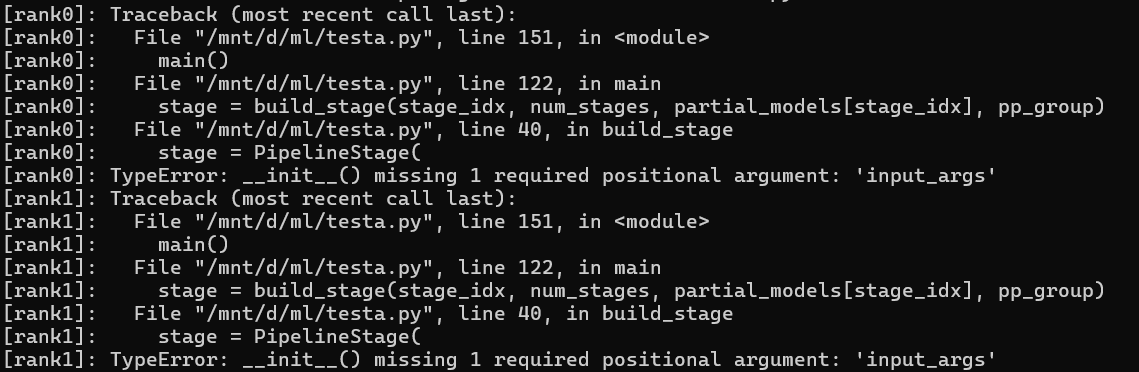
Could someone help me identify what might be going wrong here? Any advice or pointers would be greatly appreciated!