I trained a simple refinedet-512 model to test the predictive time, and found that it took about 60ms to compute with float and also 60ms to compute with half single, why?
env: GTX1660
libtorch: 1.1 with cuda 10
I trained a simple refinedet-512 model to test the predictive time, and found that it took about 60ms to compute with float and also 60ms to compute with half single, why?
env: GTX1660
libtorch: 1.1 with cuda 10
Could you share the code you’ve used to time your model?
The GTX 1660 should accelerate FP16 operations as far as I know.
I convert the entire model to FP16 with code
network->to(torch::kCUDA).to(torch::kHalf),
and also the input data (kfloat to kHalf)
input = input.to(torch::kCUDA).to(torch::kHalf).
Then I package data preprocessing, forward() and following analysis processing into a predict function, and use std::chrono to measure the elapsed time of this predict function.
Are you profiling your “complete” code, i.e. including the data loading?
Could it be that the data loading might be the bottleneck in your application or did you make sure to just time the forward and backward functions?
like this?
// matImg is a cv::Mat loaded with opencv,and convert to CV_32FC3
// m_model is already loaded
at::Tensor input = torch::from_blob(matImg.data, { 1, 512,512,3 }, torch::kFloat).to(torch::kCUDA);
input = input.permute({ 0,3,1,2 });
input = input.to(torch::kHalf);
m_model->to(torch::kHalf);
auto output = m_model->forward({ input }).toTuple();
at::Tensor arm_loc = output->elements()[0].toTensor().to(torch::kFloat).to(torch::kCUDA);
at::Tensor arm_conf = output->elements()[1].toTensor().to(torch::kFloat).to(torch::kCUDA);
at::Tensor odm_loc = output->elements()[2].toTensor().to(torch::kFloat).to(torch::kCUDA);
at::Tensor odm_conf = output->elements()[3].toTensor().to(torch::kFloat).to(torch::kCUDA);
and then following with post-processing( such as nms) to get the final result of detection.
The amount of time I count includes putting data into cuda, forward(),and post-processing, where loading data and post-processing occpuied about 10ms in 60ms
Thanks for the code.
Could you add synchronization points before starting and stopping the timer for the forward and backward pass?
at::cuda::CUDAStream stream = at::cuda::getCurrentCUDAStream();
AT_CUDA_CHECK(cudaStreamSynchronize(stream));
It would be interesting to see just the time for the actual GPU workload.
Thanks.
After adding synchronization, the partical code is as follows
std::chrono::steady_clock::time_point t1, t2;
std::chrono::duration time_used;at::cuda::CUDAStream stream = at::cuda::getCurrentCUDAStream();
AT_CUDA_CHECK(cudaStreamSynchronize(stream));
t1 = std::chrono::steady_clock::now();auto output = m_model->forward({ input }).toTuple();
AT_CUDA_CHECK(cudaStreamSynchronize(stream));
t2= std::chrono::steady_clock::now();
time_used = std::chrono::duration_cast<std::chrono::duration>(t2 - t1) * 1000;printf(“forward cost time %f ms \n”, time_used);
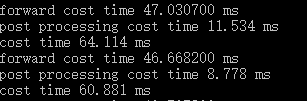
The test results are as follows, and find that fp16 is even slightly slower than fp32
FP16
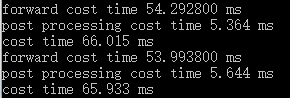
FP32