Hello,
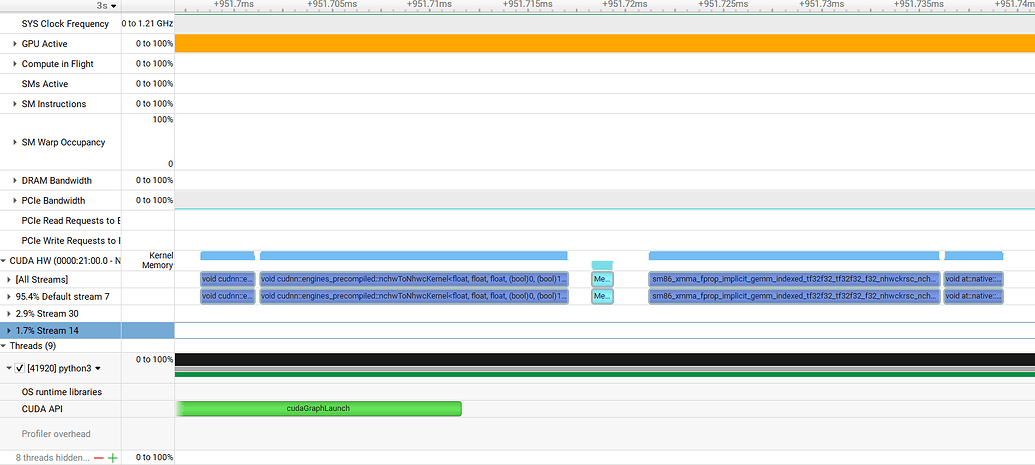
While using NVIDIA Nsight Systems to analyze the performance of a Pytorch program, I noticed an issue as shown in the attached figure: there is a significant idle period between the gpu_memset operation and the kernel executions before and after it.
Why does the gpu_memset operation result in such long kernel gaps? Can I avoid this?
Thanks!!!
And my example code is:
from torch import nn
import torch
torch.cuda.set_device(1)
conv = nn.Conv2d(384, 384, kernel_size=(3, 1), padding=(1, 0)).to(device="cuda:1").eval()
x = torch.randn(1, 384, 8, 8).to(device="cuda:1")
conv(x)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
conv(x)
g.replay()