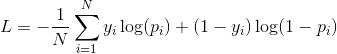On page 3 of this paper: https://arxiv.org/pdf/1511.02251.pdf there is a multi-class logistic loss:
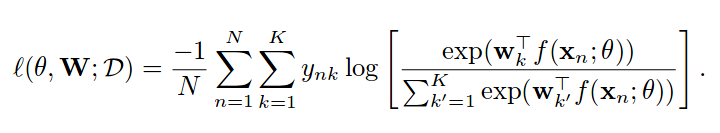
With the accompanying text:
The multi-class logistic loss minimizes the negative sum of the log-probabilities over all positive labels. Herein, the probabilities are computed using a softmax layer.
We know that multi-class means “a sample can be one of N classes where N>2”.
The loss takes a sum of positive labels (y_nk is 0 if the target is negative and 1 if the target is true), so why is this loss called a multi-class loss? The way I see it, this should be called a multi-label loss, since it will learn from multiple true labels (if an input has multiple true labels)?