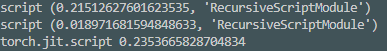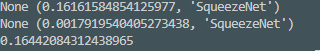I compared the performance(speed) of Torchvision’s Squeezenet original model with torch.jit.script(model) which I expected to speed up because Torchscript was asynchronous, but the original model was faster. What’s the reason? Which one did I miss?
it is not asynchronous (beyond cuda kernel launches, which is not related to jit), just python-less execution mode with optimizations
one thing I’ve seen, is that some jitted operations incorrectly enable requires_grad
but simpler explanation is that you’re not measuring it right - time the THIRD call of compiled model (actually, from your screenshot it seems you’re compiling twice [i.e. two model objects], which is also incorrect). reason is that profiling mode executor creates optimized bytecode on second call.