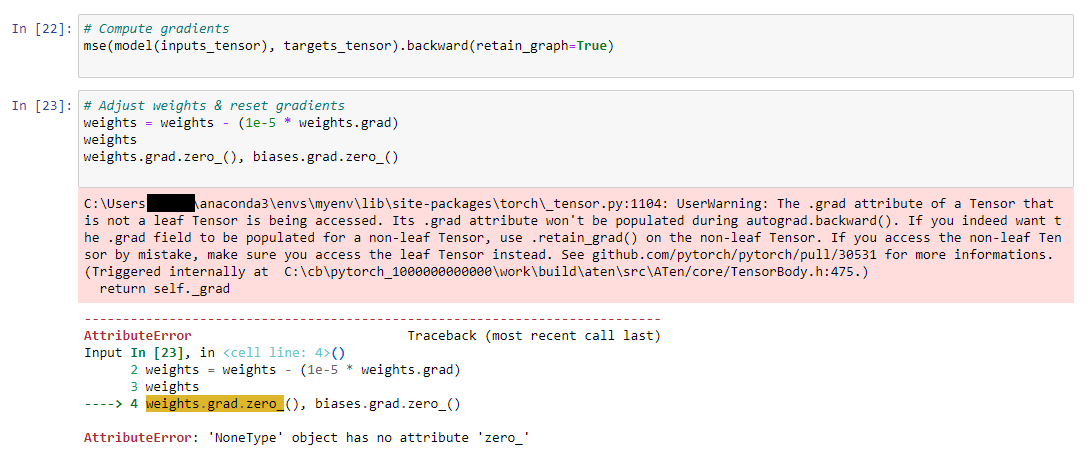
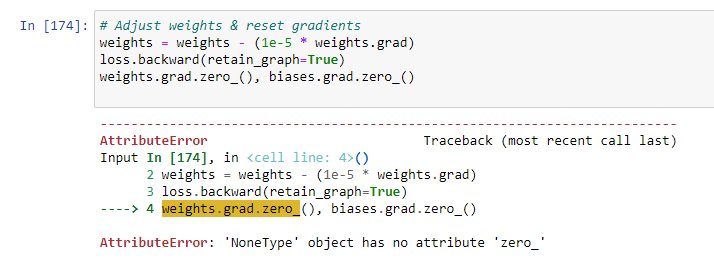
I’m in my first week of learning PyTorch and currently trying gradient descent. I’ve run into a problem where when I try to adjust the weights of my model, I get an error on my first attempt and the gradient of my weights becomes None. As far as I could see, it’s the calculation itself that causes the problem, as the gradient is still a tensor until right before the calculation.
I’m not 100% sure but it seems you’re not populating your .grad attribute when backpropagating your loss. It might happen due to you calling .backward() directly on your loss function and not the loss itself. Regardless, the following minimal reproducible example will population the .grad attributes and return gradients,
import torch
weights = torch.randn(2,3, requires_grad=True)
biases = torch.randn(2, requires_grad=True)
def model(x):
return x @ weights.t() + biases
def mse(pred, target):
diff = pred - target
diff_square = diff**2
loss = torch.mean(diff_square)
return loss
inputs=torch.randn(10,3) #random input/output data
targets=torch.randn(10,2)
loss = mse(model(inputs), targets) #define scalar loss
loss.backward() #backprop here
print(weights.grad)
print(biases.grad)
"""
returns
tensor([[ 0.0731, 0.0566, 0.0354],
[-1.4290, 0.9217, 2.7733]])
tensor([-0.3319, 1.3362])
"""
I’ve checked the gradient on every step right until the adjustment step and it is still there. But as soon as I execute the subtraction “weights = weights - (1e-5 * weights.grad)” it becomes None, while weights gets calculated correctly. Not calling backward() on my function is definitely a better idea though and better to read.
What’s probably happening then is that when you re-define weights as the difference of two tensors it most likely removes the .grad attribute which is why it gets set to None.
When updating tensors via the .grad attribute you’ll want to it within a torch.no_grad() context manager (which removes the UserWarning) but still has the .grad = None error. The .grad attribute is populated when you call .backward() so if you want the .grad again you’ll need to recompute the gradient.
You need to call loss.backward() before uses .grad as it defaults to None. Then when you update the weights the .grad attribute gets removed so there’s no need to call .grad.zero_() as it being None is the same as zeroing that Tensor.
If you want to do gradient descent, you can use the torch.optim.SGD class which will perform gradient descent too.