I have a image batch that each of them has a different shape. So I can’t batch them and have to use a for-loop instead.
my code is like below:
for image in image_batch:
out = encoder(image)
I find this encode process only used 1/4 of my GPU memory. Since I can’t increase batch_size, so I want to use multi-stream to dispatch my kernels and hope they can run in parallel. Unfortunately, the total time when dispatching samples to two stream(7.3s) is just.slightly faster than dispatching them to one stream(7.75s)
Here is my timeline when running in one stream:
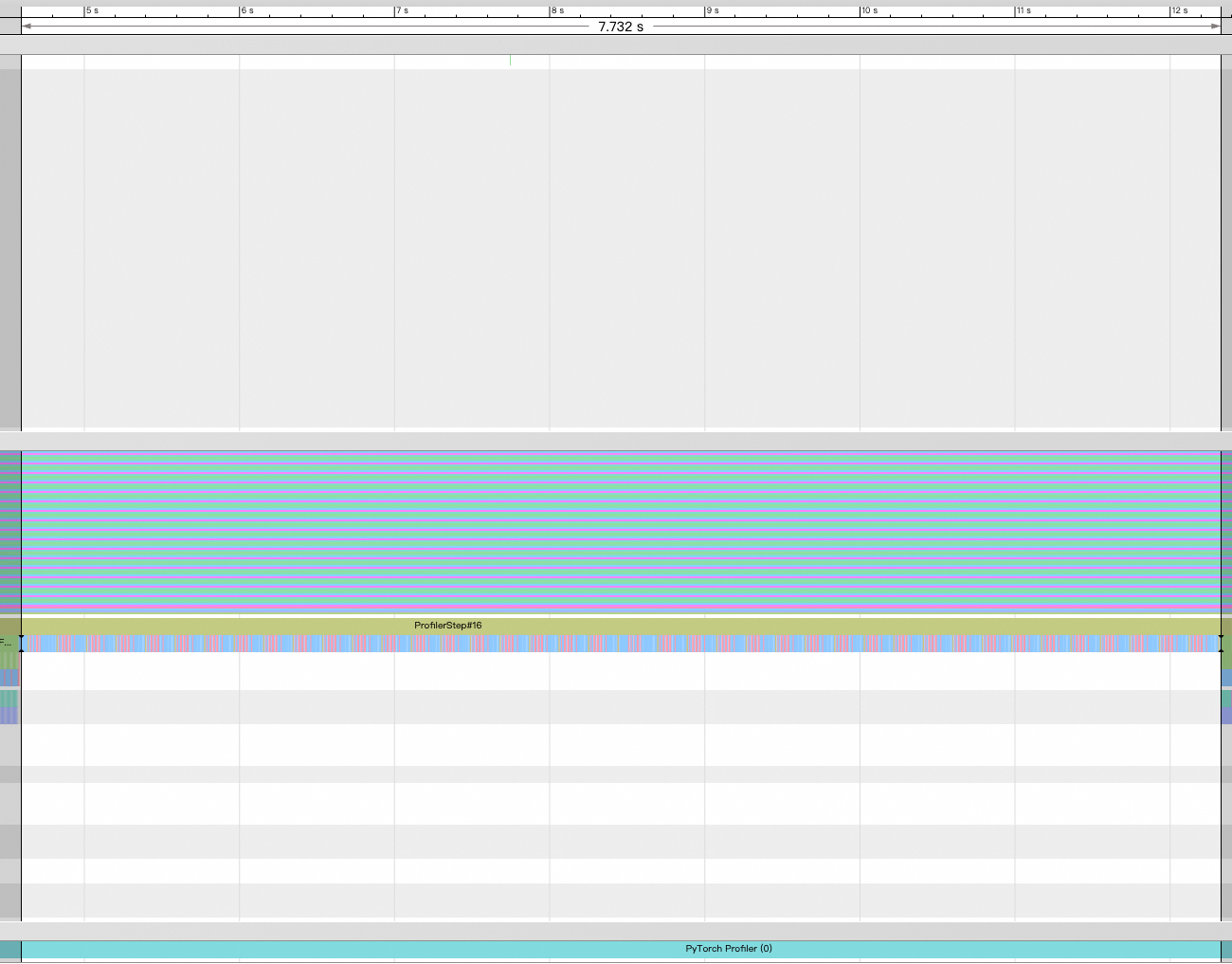
Here is timeline when running in two stream

It seems two stream version overlaps very well, but if I zoom in, I find only one kernel is running a lot time, but there are also some overlap cases
for example, element-wise kernels seems unable to run in parallel

I check their kernel config, find they often have many blocks, like grid[172800,1,1], block[128,1,1]
blocks per SM 1309, warps per SM 5236.
there are also some cases that kernels can overlap.

So,my questions are
-
So does cuda doesn’t run kernel in parallel because one kernel is able to saturate the whole gpu? But I think element-wise kernel are memory bound. Are there any way for me to make each block compute more elements and save some SMs for another kernel?
-
How to check how many SMs a kernel use(e.g. nsys or ncu). And when gpu will run kernel in differnent streams sequentially or in parallel
-
Are there other best practices for my problem

I found some posts with the same issue as mine, but they can’t fully solve my problem.