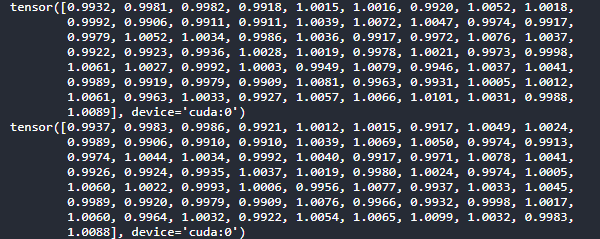
I tried to load pre-trained model parameters (in the model_se_dict variable) to a new model (in the model_se variable). I have verified that the load_state_dict method successfully loads the pre-trained parameters, where the original values have changed from 1 to another value (e.g., 0.9937).
My question is that why the model parameters in model_se_dict and model_se are not the same? For example, the first element in model_se_dict is 0.9932, while that of model_se is 0.9937…
This is weird since the parameter of model_se is assigned from the model_se_dict…
Well… I was to assign the model parameters of three pre-trained models (model_new) to a modulelist (MyModel), I tried your code and there are all matched and equal… May be I should give more codes and reproduce the errors, thanks!
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 10)
self.my_modules = nn.ModuleList([
nn.Linear(11, 11),
nn.Linear(11, 11),
nn.Linear(11, 11)
])
# setup
model = MyModel()
sd = model.state_dict()
sd_new = {}
for i in range(3):
set_seed(i)
model_new = nn.Linear(11,11)
for k,v in model_new.state_dict().items():
sd_new['my_modules.' + str(i) + '.' + k] = v
# update the dict
sd.update(sd_new)
#load the updated dict
model.load_state_dict(sd)
# # if the papameters are assigned correctly?
print(torch.all(torch.eq(model.state_dict()['my_modules.0.weight'],sd['my_modules.0.weight'])))
print(torch.all(torch.eq(model.state_dict()['my_modules.1.weight'],sd['my_modules.1.weight'])))
print(torch.all(torch.eq(model.state_dict()['my_modules.2.weight'],sd['my_modules.2.weight'])))
I also try some demo in the local PC where dense layer is implemented in my coda. Nothing is wrong. However my current case the ResNet layers are deployed
@ ptrblck, I have tried another demo and the error mentioned above occurs!
As the result in my codas, the weights in model_se_dict are not changed when epoch>0. However, the parameters of model_se.state_dict()[‘feature_ensemble.0.0.weight’] change every time when I assign weights to the other layer!
import pandas as pd
import numpy as np
import random
import scipy.io
import os
from copy import deepcopy
#gridsearch/randomsearch
from itertools import product
from tqdm import tqdm
#visualize results
import matplotlib.pyplot as plt
import time
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import Subset,DataLoader,TensorDataset
from torchvision import datasets,transforms
import torch.nn.functional as F
#resnet18, using as the backbone
from torchvision.models import resnet18
def set_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# import warnings
# warnings.filterwarnings("ignore")
if torch.cuda.is_available():
n_gpu = torch.cuda.device_count()
print(f'number of gpu: {n_gpu}')
print(f'cuda name: {torch.cuda.get_device_name(0)}')
is_cuda=True
print('GPU is on')
else:
is_cuda=False
print('GPU is off')
class unet_ensemble(nn.Module):
def __init__(self, base_model, ensemble_num:int):
super(unet_ensemble,self).__init__()
#ensemble number
self.ensemble_num = ensemble_num
#nn.modulelist
self.feature_ensemble = nn.ModuleList([base_model for _ in range(self.ensemble_num)])
def forward(self,X):
pass
saved_name = 'model_base'
seed = 42
#save base model
for i in range(5):
set_seed(i)
model = resnet18(pretrained=False)
model.add_module('fc',nn.Linear(512,1))
torch.nn.init.xavier_uniform_(model.conv1.weight)
torch.save(nn.Sequential(*list(model.children())[:-1]), os.path.join('./', saved_name + '_epoch_'+ str(i) + '.pth'))
#selected epochs for ensembling
# epochs_select = np.arange(epochs)
epochs_select = np.arange(5)
#self-ensembled model
set_seed(seed)
base_model = resnet18(pretrained=False)
base_model = nn.Sequential(*list(base_model.children())[:-1])
if is_cuda:
base_model.cuda()
#ensemble model
set_seed(seed)
model_se = unet_ensemble(base_model=base_model, ensemble_num=len(epochs_select)) #initialization
if is_cuda:
model_se.cuda()
model_se_dict = model_se.state_dict()
#loaded pretrained model parameters for each epoch
for i,epoch in enumerate(tqdm(epochs_select)):
loaded_dict = {}
loaded_dict_epoch = torch.load(os.path.join('./', saved_name + '_epoch_'+ str(epoch) + '.pth'))
for k,v in loaded_dict_epoch.state_dict().items():
loaded_dict['feature_ensemble.' + str(epoch) + '.' + k] = v
# 1. filter out unnecessary keys
loaded_dict = {k: v for k, v in loaded_dict.items() if k in model_se_dict}
# 2. overwrite entries in the existing state dict
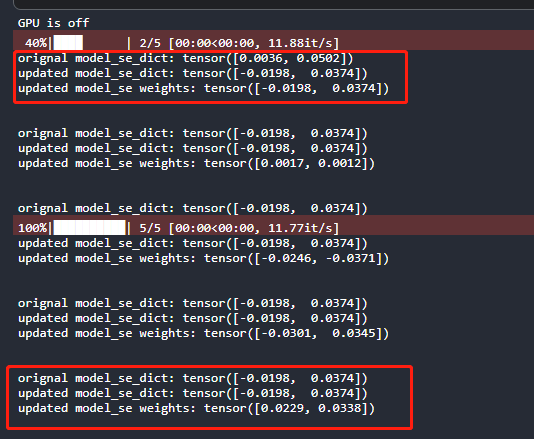
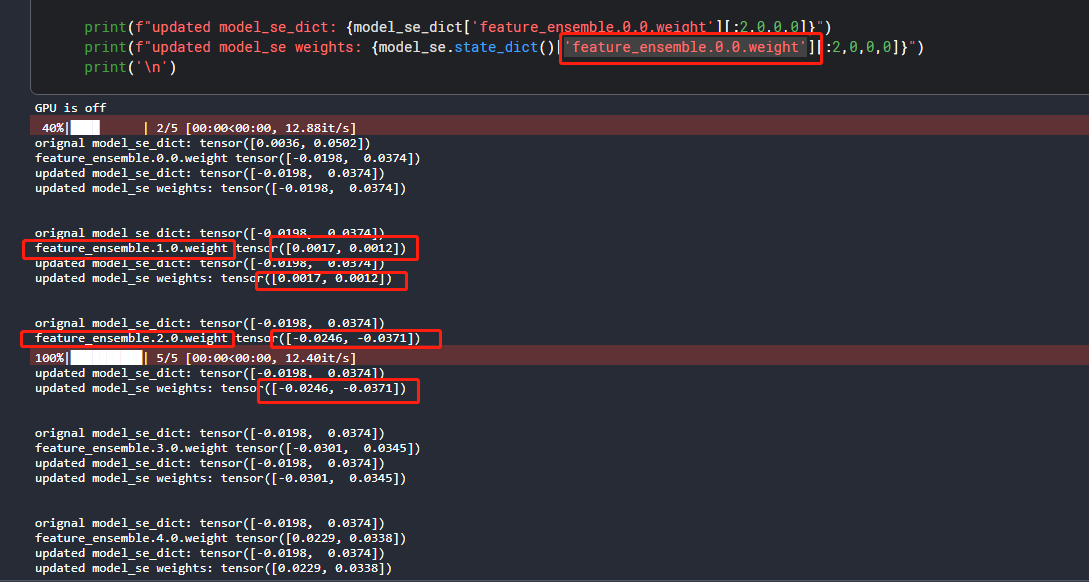
print(f"orignal model_se_dict: {model_se_dict['feature_ensemble.0.0.weight'][:2,0,0,0]}")
model_se_dict.update(loaded_dict)
# # 3. load the new state dict
model_se.load_state_dict(model_se_dict,strict=True)
print(f"updated model_se_dict: {model_se_dict['feature_ensemble.0.0.weight'][:2,0,0,0]}")
print(f"updated model_se weights: {model_se.state_dict()['feature_ensemble.0.0.weight'][:2,0,0,0]}")
print('\n')
This is the result for the above codes. As you can see, the model_se_dict only updates in the first epoch (epoch=0). However, the model parameters are changed in each epoch. Is this a BUG?
I found this error is because the weight of “feature_ensemble.0.0.weight” would be updated by other layer’s parameters (e.g., feature_ensemble.1.0.weight), and thus be updated in each epoch iteration…
This is weird since the load_state_dict method should assign model parameters based on their key, can you explain the mechanism in this situation? thanks! @ptrblck
I have found the solution. Instead of first create modulelist and assign weights for each part, the base model is created and assigned weights directly, then the base models (which has been assigned pre-trained weights) are implemented in the modulelist. The final result shows that this process is right.
But I still wonder that why the previous method is wrong. Maybe someone can explain…
import pandas as pd
import numpy as np
import random
import scipy.io
import os
from copy import deepcopy
#gridsearch/randomsearch
from itertools import product
from tqdm import tqdm
#visualize results
import matplotlib.pyplot as plt
import time
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import Subset,DataLoader,TensorDataset
from torchvision import datasets,transforms
import torch.nn.functional as F
#resnet18, using as the backbone
from torchvision.models import resnet18
def set_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# import warnings
# warnings.filterwarnings("ignore")
if torch.cuda.is_available():
n_gpu = torch.cuda.device_count()
print(f'number of gpu: {n_gpu}')
print(f'cuda name: {torch.cuda.get_device_name(0)}')
is_cuda=True
print('GPU is on')
else:
is_cuda=False
print('GPU is off')
class unet_ensemble(nn.Module):
def __init__(self, base_model_list):
super(unet_ensemble,self).__init__()
#nn.modulelist
self.feature_ensemble = nn.ModuleList([_ for _ in base_model_list])
def forward(self,X):
pass
saved_name = 'model_base'
seed = 42
#save base model
for i in range(5):
set_seed(i)
model = resnet18(pretrained=False)
model.add_module('fc',nn.Linear(512,1))
torch.nn.init.xavier_uniform_(model.conv1.weight)
torch.save(nn.Sequential(*list(model.children())[:-1]), os.path.join('./', saved_name + '_epoch_'+ str(i) + '.pth'))
#selected epochs for ensembling
base_model_list = []
#loaded pretrained model parameters for each epoch
for epoch in tqdm(range(5)):
set_seed(seed)
base_model = resnet18(pretrained=False)
base_model = nn.Sequential(*list(base_model.children())[:-1])
if is_cuda:
base_model.cuda()
loaded_dict_epoch = torch.load(os.path.join('./', saved_name + '_epoch_'+ str(epoch) + '.pth'))
base_model.load_state_dict(loaded_dict_epoch.state_dict())
base_model_list.append(base_model)
#ensemble model
set_seed(seed)
model_se = unet_ensemble(base_model_list=base_model_list) #initialization
if is_cuda:
model_se.cuda()
#验证
verify = []
for i in range(5):
loaded_dict_epoch = torch.load(os.path.join('./', saved_name + '_epoch_'+ str(epoch) + '.pth'))
for k,v in loaded_dict_epoch.state_dict().items():
verify.append(torch.all(torch.eq(model_se.state_dict()['feature_ensemble.' + str(epoch) + '.' + k], loaded_dict_epoch.state_dict()[k])))
print(torch.all(torch.tensor(verify)))
print(model_se.state_dict()['feature_ensemble.0.0.weight'][:2,0,0,0])
print(model_se.state_dict()['feature_ensemble.4.0.weight'][:2,0,0,0])