Hi everyone,
I am using Pytorch to perform non-linear regression. I have been using the Adam optimizer. It seems that no matter what data I use, or how small I make the learning rate, eventually the loss plot becomes noisier and noisier as the epochs go on. I am wondering why this happens. I have included an example plot to show what I mean.
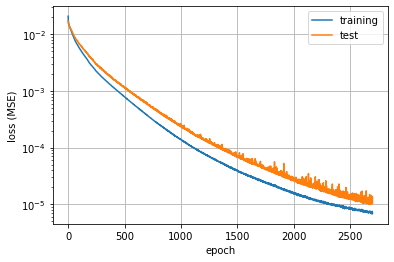
Depending on what data I’m using or how large I make the learning rate, this increase in the noisiness can be more or less severe. I also noticed that this increase in the noise happens for both the training loss and the testing loss, but that the magnitude of the noise is always greater for the test data.
So is this something that is just inherent to the optimization process, and how it searches through the loss landscape? Is this just an unavoidable aspect of the optimization?
Hello, just a shot in the dark here but is it possible that your datapoints are differently noisy from one another? If so, depending on whether you happen to over- or under-sample the noisier datapoints in a given epoch, you may get more or less randomness in your parameter changes, leading to jitter in MSE. If you’re using a random sampler, this may well be happening. This could be due to the raw datapoints themselves, or to the transformed ones (in case you’re applying some transforms).
If this is being induced by the transforms, you can try training without transforms (maybe starting at a certain epoch) and see if the stutter goes away.
If it’s due to the raw datapoints being inherently noisy in some way, you can try to specifically diagnose this. It’s a bit of work, but you can keep a measure per datapoint of whether the number of times a particular datapoint is included in an epoch is correlated with the subsequent change in validation error. If you find that some datapoints spike on this measure (meaning, the more often they are sampled in the epoch, the higher the subsequent validation / test MSE increase) then you can have a look at them and decide if they are perhaps worth excluding from training beyond a certain epoch.
1 Like
Expanding on from what @Andrei_Cristea has already said, you need to realize that the magnitude of these oscillations is pretty small. The current loss is on the order of 1e-5, and these oscillations are similarly on the order of 1e-5. This could be because of the stochastic nature of the sampling process, or it could be a result of the optimizer.
Could you try this again but with say torch.optim.SGD and see if the same oscillations occur?
Because Adam uses moments of the gradient to precondition your learning rate by a preconditioning factor, and near the local minima these values will become near zero. In the denominator of this preconditioning factor, you’ll have something like torch.sqrt(second_moment) + epsilon. In the limit of epsilon (which defaults to 1e-8) being larger than torch.sqrt(second_moment) you’ll effectively be multiplying the numerator of the preconditioning factor by 1/epsilon (which will default to 1e8). This could cause the optimizer to overshoot a local minima which will lead to these oscillations. As the optimizer constantly tries to update towards the local minima.
Also, the loss minimization isn’t guaranteed to be monotonic so seeing oscillations within the loss is expected behavior. You could try running torch.optim.Adam with a learning rate scheduler and see if the oscillations diminish. But then again, having a loss of 1e-5 is perfectly acceptable already.
2 Likes
@AlphaBetaGamma96 You gave me an idea. Since I’m plotting the loss on a log scale, perhaps the noisiness is actually constant throughout the epochs, but it only becomes visible once the scale reaches 1e-5. I’ll look into this, and if this isn’t the cause, then I’ll try running with SGD. I’ll report back on my findings 