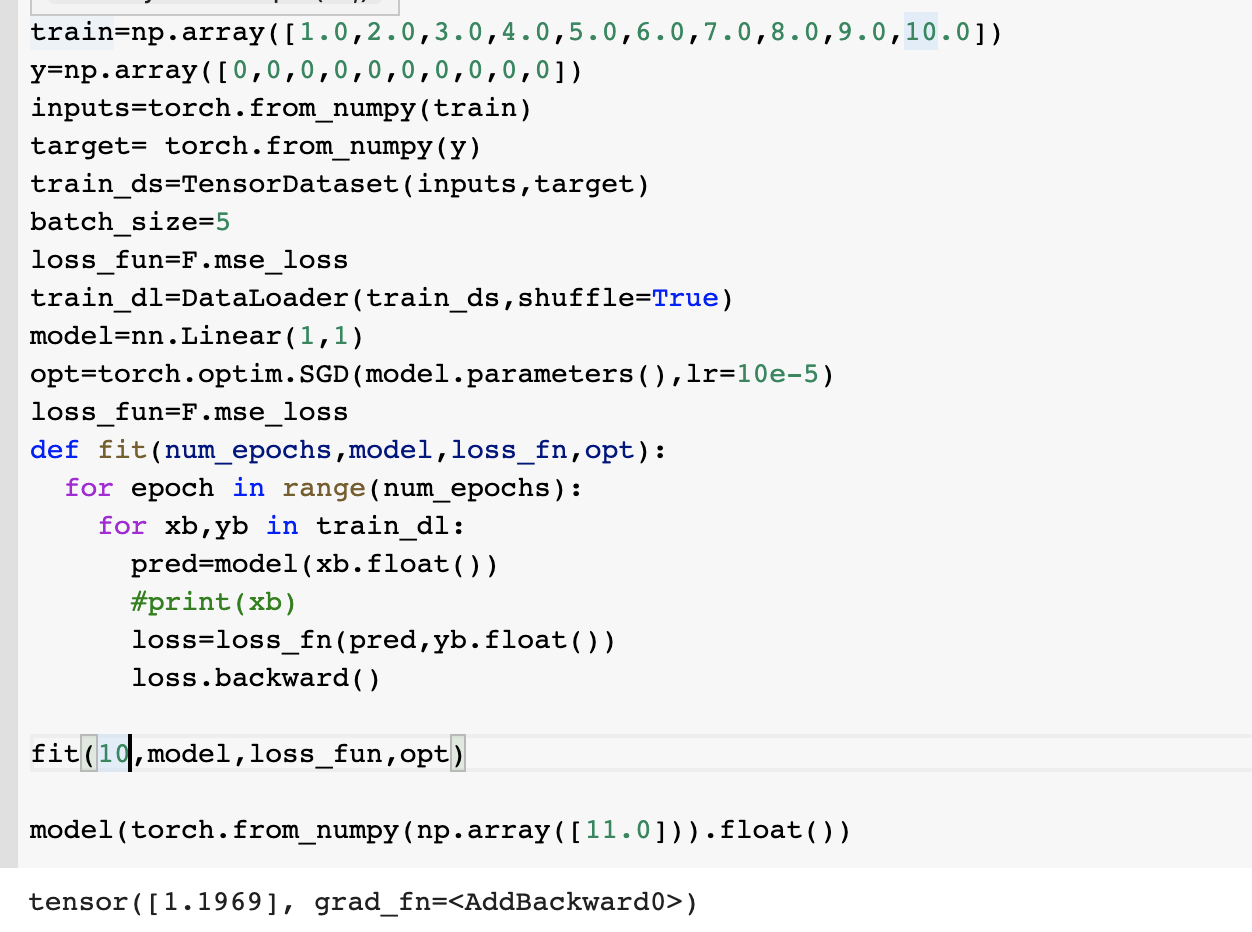
Your training loop misses the optimizer.step() call so the parameters of your model won’t be updated.
I would recommend to take a look at the tutorials and play around with some of these models and training loops first.
PS: you can post code snippets by wrapping them into three backticks ```, which makes debugging easier. 
Thank you @ptrblck Is the code corrected now?
y=np.array([0,1,0,1,0,1,0,1,0,1])
inputs=torch.from_numpy(train)
target= torch.from_numpy(y)
train_ds=TensorDataset(inputs,target)
batch_size=5
loss_fun=F.mse_loss
train_dl=DataLoader(train_ds,shuffle=True)
model=nn.Linear(1,1)
opt=torch.optim.SGD(model.parameters(),lr=10e-5)
loss_fun=F.mse_loss
def fit(num_epochs,model,loss_fn,opt):
for epoch in range(num_epochs):
for xb,yb in train_dl:
pred=model(xb.float())
#print(xb)
loss=loss_fn(pred,yb.float())
loss.backward()
opt.step()
opt.zero_grad()
# if (epoch+1) % 10 == 0:
# print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
fit(10000,model,loss_fun,opt)
model(torch.from_numpy(np.array([11.0])).float())```It looks alright for a toy example, yes.