This is a repost from the computer vision category as I didn’t see that there was an audio category ![]()
Here is my problem:
I am currently working on building a CNN for sound classification. The problem is relatively simple: I need my model to detect whether there is human speech on .wav recording sounds of a tropical ecosystem. I made a train / test set containing records of 3 seconds on which there is human speech (speech) or not (no_speech). From these 3 seconds fragments I get a mel-spectrogram of dimension 128 x 128 that is used to feed the model.
I checked if the script Audiodataset (given below) gives an expected output and I can’t find any problems. For the category “speech” the mel-spectrograms look similar to:
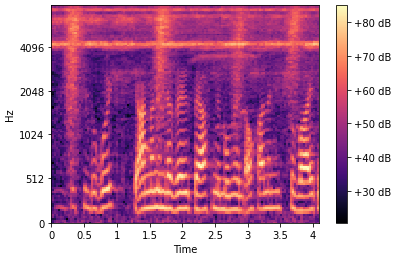
While the mel-spectrograms for “no-speech” look like:
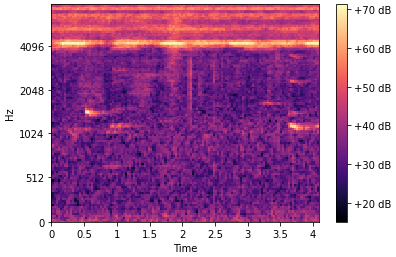
Since it is a simple binary problem I thought the a CNN would easily detect human speech but I may have been too cocky. However, it seems that after 1 or 2 epoch the model doesn’t learn anymore, i.e. the loss doesn’t decrease and the number of correct prediction stays roughly the same. I tried to play with the hyperparameters but the problem is still the same. I tried a learning rate of 0.1, 0.01 … until 1e-7. Here are the runs displayed in Tensorboard:
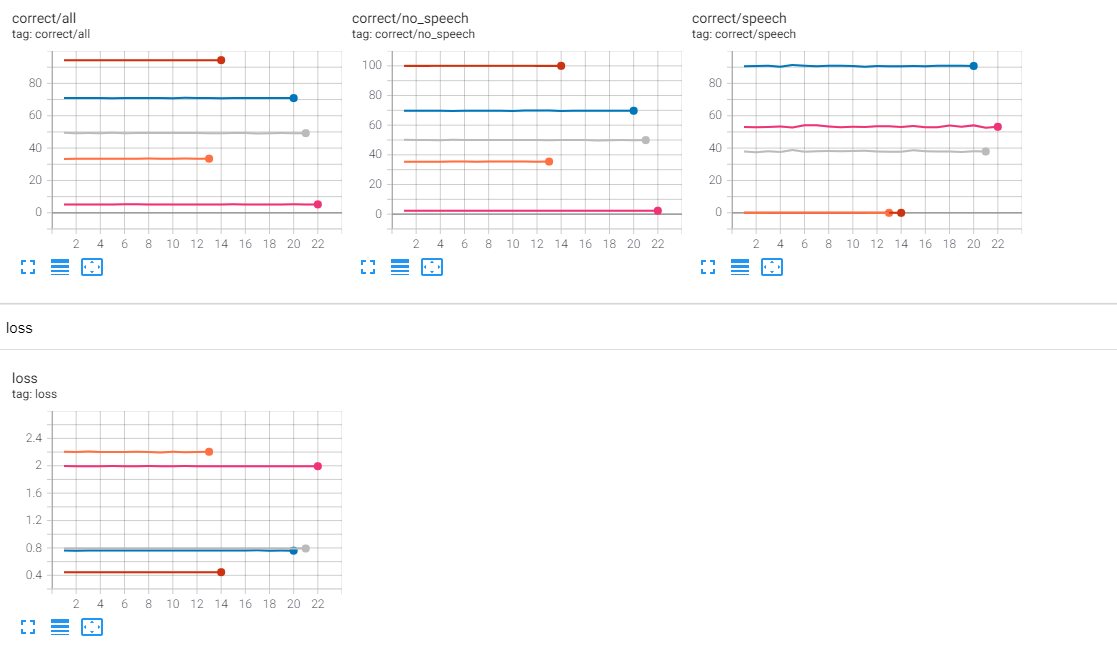
Then I thought it could be due to the script itself but I cannot find anything wrong. I would be glad you could have a quick look at the script and let me know what could go wrong! If you have other ideas of why this problem may occur I would also be glad to receive some advice on how to best train my CNN ![]()
I based the script on the LunaTrainingApp from “Deep learning in PyTorch” by Stevens as I found the script to be elegant. Of course I modified it to match my problem.
Here is the script creating the input for the model (from .wav file to mel-spectrogram):
"""
Define a class AudioDataset which take the folder of the training / test data as input
and make normalized mel-spectrograms out of it
Labels are also one hot encoded
"""
from torch.utils.data import Dataset
from pydub import AudioSegment
from sklearn.preprocessing import LabelEncoder
from fs import open_fs
from fs.osfs import OSFS
import numpy as np
import librosa
import torch
import os
class AudioDataset(Dataset):
def __init__(self, data_root, n_fft, hop_length, n_mels):
self.data_root_fs = open_fs(data_root)
self.samples = []
self.n_fft = n_fft
self.hop_length = hop_length
self.n_mels = n_mels
self.class_encode = LabelEncoder()
self._init_dataset()
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
audio_filepath, label = self.samples[idx]
with self.data_root_fs.open(audio_filepath, 'rb') as audio_fd:
audio_file = AudioSegment.from_file(audio_fd)
#audio_file = AudioSegment.from_file(audio_filepath)
array_audio = np.array(audio_file.get_array_of_samples(), dtype=float)
mel = self.to_mel_spectrogram(array_audio)
#mel_norm = self.normalize_row_matrix(mel)
mel_norm_tensor = torch.tensor(mel)
mel_norm_tensor = mel_norm_tensor.unsqueeze(0)
label_encoded = self.one_hot_sample(label)
label_class = torch.argmax(label_encoded)
return (mel_norm_tensor, label_class)
def _init_dataset(self):
folder_names = set()
for match in self.data_root_fs.glob("*/*.wav"):
folder = match.path.split('/')[-2]
folder_names.add(folder)
self.samples.append((match.path, folder))
self.class_encode.fit(list(folder_names))
def to_mel_spectrogram(self, x):
sgram = librosa.stft(x, n_fft=self.n_fft, hop_length=self.hop_length)
sgram_mag, _ = librosa.magphase(sgram)
mel_scale_sgram = librosa.feature.melspectrogram(S=sgram_mag, sr=16000, n_mels=self.n_mels)
mel_sgram = librosa.amplitude_to_db(mel_scale_sgram)
return mel_sgram
def normalize_row_matrix(self, mat):
mean_rows = mat.mean(axis=1)
std_rows = mat.std(axis=1)
normalized_array = (mat - mean_rows[:, np.newaxis]) / std_rows[:, np.newaxis]
return normalized_array
def to_one_hot(self, codec, values):
value_idxs = codec.transform(values)
return torch.eye(len(codec.classes_))[value_idxs]
def one_hot_sample(self, label):
t_label = self.to_one_hot(self.class_encode, [label])
return t_label
The model itself, which basically performs 2D convolutions on the mel-spectrogram:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class VADNet(nn.Module):
def __init__(self, in_channels=1, conv_channels=8):
super().__init__()
self.tail_batchnorm = nn.BatchNorm2d(1)
self.block1 = ConvBlock(in_channels, conv_channels)
self.block2 = ConvBlock(conv_channels, conv_channels * 2)
self.block3 = ConvBlock(conv_channels * 2, conv_channels * 4)
self.block4 = ConvBlock(conv_channels * 4, conv_channels * 8)
self.head_linear = nn.Linear(8 * 8 * conv_channels * 8, 2)
self._init_weights()
def _init_weights(self):
for m in self.modules():
if type(m) in {
nn.Linear,
nn.Conv3d,
nn.Conv2d,
nn.ConvTranspose2d,
nn.ConvTranspose3d,
}:
nn.init.kaiming_normal_(
m.weight.data, a=0, mode='fan_out', nonlinearity='relu',
)
if m.bias is not None:
fan_in, fan_out = \
nn.init._calculate_fan_in_and_fan_out(m.weight.data)
bound = 1 / math.sqrt(fan_out)
nn.init.normal_(m.bias, -bound, bound)
def forward(self, input_batch):
bn_output = self.tail_batchnorm(input_batch)
block_out = self.block1(bn_output)
block_out = self.block2(block_out)
block_out = self.block3(block_out)
block_out = self.block4(block_out)
conv_flat = block_out.view(block_out.size(0),-1)
linear_output = self.head_linear(conv_flat)
return linear_output
class ConvBlock(nn.Module):
def __init__(self, in_channels, conv_channels):
super().__init__()
self.conv1 = nn.Conv2d(
in_channels, conv_channels, kernel_size=3, padding=1, bias=True,
)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(
conv_channels, conv_channels, kernel_size=3, padding=1, bias=True,
)
self.relu2 = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(2, 2)
def forward(self, input_batch):
block_out = self.conv1(input_batch)
block_out = self.relu1(block_out)
block_out = self.conv2(block_out)
block_out = self.relu2(block_out)
return self.maxpool(block_out)
And the script that I use for training the model:
import torch
import torch.nn as nn
import argparse
import numpy as np
import logging
logging.basicConfig(level = logging.INFO)
log = logging.getLogger(__name__)
from torch.optim import SGD
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from sklearn.metrics import confusion_matrix
from dataset_loader.audiodataset import AudioDataset
from models.vadnet import VADNet
from utils.earlystopping import EarlyStopping
class VADTrainingApp:
def __init__(self, sys_argv=None):
parser = argparse.ArgumentParser()
parser.add_argument("--train_path",
help='Path to the training set',
required=True,
type=str,
)
parser.add_argument("--test_path",
help='Path to the testing set',
required=True,
type=str,
)
parser.add_argument("--save_path",
help='Path to saving the model',
required=True,
type=str,
)
parser.add_argument("--save_es",
help='Save the checkpoints of early stopping call',
default="checkpoint.pt",
type=str,
)
parser.add_argument('--num-workers',
help='Number of worker processes for background data loading',
default=8,
type=int,
)
parser.add_argument("--batch_size",
help='Batch size to use for training',
default=32,
type=int,)
parser.add_argument('--epochs',
help='Number of epochs to train for',
default=50,
type=int,
)
parser.add_argument('--lr',
help='Learning rate for th stochastic gradient descent',
default=0.001,
type=float,
)
self.cli_args = parser.parse_args(sys_argv)
# related to the hardware
self.use_cuda = torch.cuda.is_available()
self.device = torch.device("cuda" if self.use_cuda else "cpu")
# directly related to the neural network
self.model = self.initModel()
self.optimizer = self.initOptimizer()
# For early stopping
self.patience = 7
# For metrics
self.METRICS_LABELS_NDX = 0
self.METRICS_PREDS_NDX = 1
self.METRICS_LOSS_NDX = 2
self.METRICS_SIZE = 3
def initModel(self):
"""Initialize the model, if GPU available computation done there"""
model = VADNet()
model = model.double()
if self.use_cuda:
log.info("Using CUDA; {} devices".format(torch.cuda.device_count()))
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
model = model.to(self.device)
return model
def initOptimizer(self):
return SGD(self.model.parameters(), lr=self.cli_args.lr)#, momentum=0.8, weight_decay=0.01)
def adjust_learning_rate(self):
"""Sets the learning rate to the initial LR decayed by a factor of 10 every 20 epochs"""
self.cli_args.lr = self.cli_args.lr * (0.1 ** (self.cli_args.epochs // 20))
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.cli_args.lr
def initTrainDL(self):
trainingset = AudioDataset(self.cli_args.train_path,
n_fft=1024,
hop_length=376,
n_mels=128)
batch_size = self.cli_args.batch_size
if self.use_cuda:
batch_size *= torch.cuda.device_count()
trainLoader = DataLoader(trainingset,
batch_size = batch_size,
shuffle=True,
num_workers=self.cli_args.num_workers,
pin_memory=self.use_cuda)
return trainLoader
def initTestDL(self):
testset = AudioDataset(self.cli_args.test_path,
n_fft=1024,
hop_length=376,
n_mels=128)
batch_size = self.cli_args.batch_size
if self.use_cuda:
batch_size *= torch.cuda.device_count()
testLoader = DataLoader(testset,
batch_size = batch_size,
shuffle=True,
num_workers=self.cli_args.num_workers,
pin_memory=self.use_cuda)
return testLoader
def main(self):
log.info("Start training, {}".format(self.cli_args))
train_dl = self.initTrainDL()
test_dl = self.initTestDL()
trn_writer = SummaryWriter(log_dir='runs' + '-trn')
val_writer = SummaryWriter(log_dir='runs' + '-val')
early_stopping = EarlyStopping(patience=self.patience, path=self.cli_args.save_es, verbose=True)
for epoch_ndx in range(1, self.cli_args.epochs + 1):
log.info("Epoch {} / {}".format(epoch_ndx, self.cli_args.epochs))
# Adjust the new learning rate
self.adjust_learning_rate()
# Train the model's parameters
metrics_t = self.do_training(train_dl)
self.logMetrics(metrics_t, trn_writer, epoch_ndx)
# Test the model
metrics_v = self.do_val(test_dl, val_writer)
self.logMetrics(metrics_v, val_writer, epoch_ndx, train=False)
# Add the mean loss of the val for the epoch
early_stopping(metrics_v[self.METRICS_LOSS_NDX].mean(), self.model)
if early_stopping.early_stop:
print("Early stopping")
break
# Save the model once all epochs have been completed
torch.save(self.model.state_dict(), self.cli_args.save_path)
def do_training(self, train_dl):
"""Training loop"""
self.model.train()
# Initiate a 3 dimension tensor to store loss, labels and prediction
trn_metrics = torch.zeros(self.METRICS_SIZE, len(train_dl.dataset), device=self.device)
for batch_ndx, batch_tup in enumerate(train_dl):
if batch_ndx%100==0:
log.info("TRAINING --> Batch {} / {}".format(batch_ndx, len(train_dl)))
self.optimizer.zero_grad()
loss = self.ComputeBatchLoss(batch_ndx,
batch_tup,
self.cli_args.batch_size,
trn_metrics)
loss.backward()
self.optimizer.step()
return trn_metrics.to('cpu')
def do_val(self, test_dl, early_stop):
"""Validation loop"""
with torch.no_grad():
self.model.eval()
val_metrics = torch.zeros(self.METRICS_SIZE, len(test_dl.dataset), device=self.device)
for batch_ndx, batch_tup in enumerate(test_dl):
if batch_ndx%100==0:
log.info("VAL --> Batch {} / {}".format(batch_ndx, len(test_dl)))
loss = self.ComputeBatchLoss(batch_ndx,
batch_tup,
self.cli_args.batch_size,
val_metrics)
return val_metrics.to('cpu')
def ComputeBatchLoss(self, batch_ndx, batch_tup, batch_size, metrics_mat):
"""
Return a tensor the loss of the batch
"""
imgs, labels = batch_tup
imgs = imgs.to(device=self.device, non_blocking=True)
labels = labels.to(device=self.device, non_blocking=True)
outputs = self.model(imgs)
_, predicted = torch.max(outputs, dim=1)
loss_func = nn.CrossEntropyLoss(reduction="none")
loss = loss_func(outputs, labels)
start_ndx = batch_ndx * self.cli_args.batch_size
end_ndx = start_ndx + labels.size(0)
metrics_mat[self.METRICS_LABELS_NDX, start_ndx:end_ndx] = labels.detach()
metrics_mat[self.METRICS_PREDS_NDX, start_ndx:end_ndx] = predicted.detach()
metrics_mat[self.METRICS_LOSS_NDX, start_ndx:end_ndx] = loss.detach()
return loss.mean()
def logMetrics(self, metrics_mat, writer, epoch_ndx, train=True):
"""
Function to compute custom metrics: accurracy and recall for both classes
and % of correct predictions. Log the metrics in a tensorboard writer
"""
# Confusion matrix to compute precision / recall for each class
tn, fp, fn, tp = torch.tensor(confusion_matrix(metrics_mat[self.METRICS_LABELS_NDX],
metrics_mat[self.METRICS_PREDS_NDX],
labels=[0,1]).ravel())
precision_no_speech = tp / (tp + fp)
recall_no_speech = tp / (tp + fn)
# class speech is labelled 0, so true positive = true negative for speech
precision_speech = tn / (tn + fn)
recall_speech = tn / (fp + tn)
# % of correct predictions - optional metrics that are nice
no_speech_count = (metrics_mat[self.METRICS_LABELS_NDX] == 0).sum()
speech_count = (metrics_mat[self.METRICS_LABELS_NDX] == 1).sum()
no_speech_correct = ((metrics_mat[self.METRICS_PREDS_NDX] == 0) & (metrics_mat[self.METRICS_LABELS_NDX] == 0)).sum()
speech_correct = ((metrics_mat[self.METRICS_PREDS_NDX] == 1) & (metrics_mat[self.METRICS_LABELS_NDX] == 1)).sum()
correct_all = (speech_correct + no_speech_correct) / float(speech_count + no_speech_count) * 100
correct_speech = speech_correct / float(speech_count) * 100
correct_no_speech = no_speech_correct / float(no_speech_count) * 100
loss = metrics_mat[self.METRICS_LOSS_NDX].mean()
writer.add_scalar("loss", loss, epoch_ndx)
writer.add_scalar("precision/no_speech", precision_no_speech, epoch_ndx)
writer.add_scalar("recall/no_speech", recall_no_speech, epoch_ndx)
writer.add_scalar("precision/speech", precision_speech, epoch_ndx)
writer.add_scalar("recall/speech", recall_speech, epoch_ndx)
writer.add_scalar("correct/all", correct_all, epoch_ndx)
writer.add_scalar("correct/speech", correct_speech, epoch_ndx)
writer.add_scalar("correct/no_speech", correct_no_speech, epoch_ndx)
if train:
log.info("[TRAINING] loss: {}, correct/all: {}% , correct/speech: {}%, correct/no_speech: {}%".format(loss,
correct_all,
correct_speech,
correct_no_speech))
else:
log.info("[VAL] loss: {}, correct/all: {}% , correct/speech: {}%, correct/no_speech: {}%".format(loss,
correct_all,
correct_speech,
correct_no_speech))
if __name__ == "__main__":
VADTrainingApp().main()
I tried to fit the model on a small subset of the data but the problem remains. I would be very grateful for any help as this problem is getting frustrating ![]()
Thank you!