Say I have C classes, and I want to get a C*C similarity matrix in which each entry is the cosine similarity between class_i and class_j. I write the below code to compute the similar loss based on the weights of last but one fc layer. Below is the part of the code for simplicity:
Why my loss_sim doesn’t work for my training process? It seems that the loss_sim didn’t backward properly to affect the original model weights.
I know we can wrap the loss function into a class like:
class Loss_sim(nn.Module):
def __init__():
def forward(self, weights):
Should I write like this? Is any problem here because of the copy of the original weights?
Thanks in advance
place zeros on the diagonal of sim_mat so that max_val can
never be negative.
The problem is that the rows of weights can all have negative
cosine similarity with one another, at which point loss_sim becomes
zero, has zero gradient, and no longer contributes to the training.
After quoting your code, I show a script that runs your version
of loss_sim packaged as a function, cc_sim, and compares it
with two possibly improved versions. cc_simA returns the mean
of the cosine similarities, while cc_simB removes the floor
of zero on loss_sim so that it can become negative and fall
to its most negative similarity (maximum dissimilarity).
This script shows that your version does backpropagate, but does
get stuck at zero, and that the improved versions don’t get stuck
at zero.
It also give an example of a tensor, t, whose rows all have
negative cosine similarity with one another.
Thank you for your timely help. Basically, I want to penalize the most similar pairs of each class. That’s why I want to get a similar loss which serves as a regularizing term. My total loss is like L_total = L_CE + L_sim. My questions as follows:
I want to know if this term can help to update the parameters of my network in the training process cause I did an assignment for model weights here weights = self.model.module.model.fc[-1].weight.
If I want to get a weighed similar loss, is the below code based on yours correct?
import torch
torch.__version__
torch.random.manual_seed (2020)
def cc_sim (weights, w_s):
'''
weights: weights from NN model
w_s: weights for every entry in similarity matrix, w_s.size = (num_classes, num_classes)
'''
cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
num_iter = num_classes = weights.size(0)
# similarity matrix
sim_mat = torch.empty(0, num_iter)
for j in range(num_iter):
weights_i = weights[j, :].expand_as(weights)
sim = cos(weights, weights_i)
sim = torch.unsqueeze(sim, 0)
sim_mat = torch.cat((sim_mat, sim), 0)
sim_mat = sim_mat * w_s
sim_mat = sim_mat - torch.diag(torch.diag(sim_mat))
max_val = torch.max(sim_mat, dim=1).values
loss_sim = (torch.sum(max_val) / num_classes**2)
return loss_sim
def cc_simA (weights, w_s):
'''
weights: weights from NN model
w_s: weights for every entry in similarity matrix, w_s.size = (num_classes, num_classes)
'''
cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
num_iter = num_classes = weights.size(0)
# similarity matrix
sim_mat = torch.empty(0, num_iter)
for j in range(num_iter):
weights_i = weights[j, :].expand_as(weights)
sim = cos(weights, weights_i)
sim = torch.unsqueeze(sim, 0)
sim_mat = torch.cat((sim_mat, sim), 0)
# element-wise multiply
sim_mat = sim_mat * w_s
sim_mat = sim_mat - torch.diag(torch.diag(sim_mat))
loss_sim = torch.mean (sim_mat)
return loss_sim
def cc_simB (weights, w_s):
'''
weights: weights from NN model
w_s: weights for every entry in similarity matrix, w_s.size = (num_classes, num_classes)
'''
cos = torch.nn.CosineSimilarity(dim=1, eps=1e-6)
num_iter = num_classes = weights.size(0)
# similarity matrix
sim_mat = torch.empty(0, num_iter)
for j in range(num_iter):
weights_i = weights[j, :].expand_as(weights)
sim = cos(weights, weights_i)
sim = torch.unsqueeze(sim, 0)
sim_mat = torch.cat((sim_mat, sim), 0)
# element-wise multiply
sim_mat = sim_mat * w_s
sim_mat = sim_mat - torch.diag (float ('inf') * torch.ones (num_classes))
max_val = torch.max(sim_mat, dim=1).values
loss_sim = (torch.sum(max_val) / num_classes**2)
return loss_sim
if __name__ == '__main__':
num_classes = nDim = 10
weights = torch.randn((num_classes, nDim), requires_grad=True)
w_s = torch.FloatTensor(num_classes, num_classes).uniform_(0, 1)
loss = cc_simB(weights, w_s)
loss.backward()
print('loss item:', loss)
print('grad of weights:\n')
print(weights.grad)
will prevent gradients from flowing back through the assignment
and break backpropagation, the answer is no.
In python, “variables” are references.
self.model.module.model.fc[-1].weight refers to a tensor
in memory somewhere. The above assignment creates a new
reference that refers to the same tensor in memory. No new
tensor is created, nor is any data copied from one place to
another. Performing tensor operations on weights is essentially
identical to performing tensor operations on self.model.module.model.fc[-1].weight, so backpropagation
will work identically.
would be almost equivalent to your assignment, with the only
difference being the three extra (and unnecessary) temporary
references that will be cleaned up when your script exits (or
when an enclosing code block goes out of scope).
This will do what I believe you want. Each element of sim_mat
will be multiplied by the corresponding element of w_s. This
will potentially change the result of torch.max(), depending on
the specific values involved.
Note, if you set up w_s so that it has zeros along its diagonal, the
multiplication will zero out the diagonal of sim_mat so you can forgo sim_mat = sim_mat - torch.diag(torch.diag(sim_mat)).
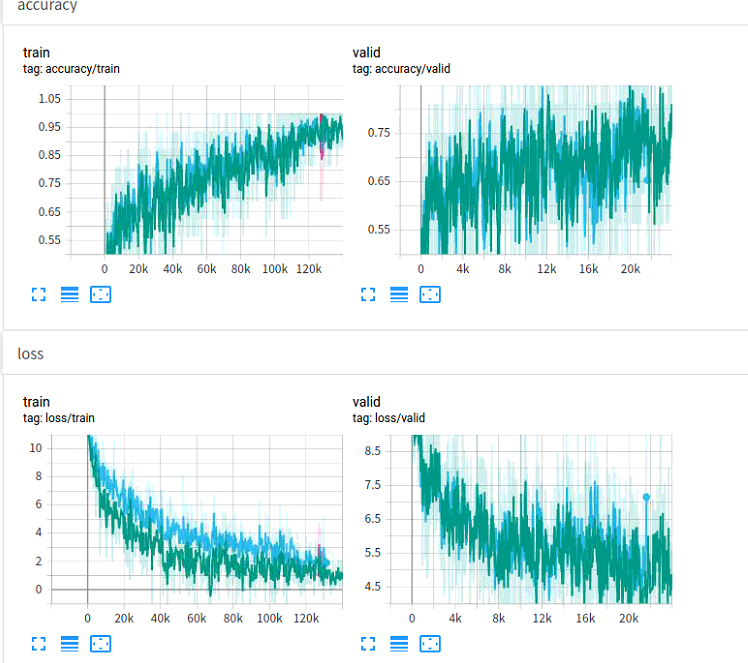
Why my training and validation accuracy curves remained almost the same after I added the sim_loss term like above cc_simB ? (Green is with sim_loss) It’s really wired.